Increasingly, individuals are turning to social media and online forums such as Twitter and Reddit to communicate about a range of issues including their health and well-being, public health concerns, and large public events such as the presidential debates. These user-generated social media data are prone to noise and misinformation. Developing and applying Artificial Intelligence (AI) algorithms can enable researchers to glean pertinent information from social media and online forums for a range of uses. For example, patients’ social media data may include information about their lifestyle that might not typically be reported to clinicians; however, this information may allow clinicians to provide individualized recommendations for managing their patients’ health. Separately, insights obtained from social media data can aid government agencies and other relevant institutions in better understanding the concerns of the populace as it relates to public health issues such as COVID-19 and its long-term effects on the well-being of the public. Finally, insights obtained from social media posts can capture how individuals react to an event and can be combined with other data sources, such as videos, to create multimedia summaries. In all these examples, there is much to be gained by applying AI algorithms to user-generated social media data.
In this talk, I will discuss my work in creating and applying AI algorithms that harness data from various sources (online forums, electronic medical records, and health care facility ratings) to gain insights about health and well-being and public health. I will also discuss the development of an algorithm for resolving pronoun mentions in event-related social media comments and a pipeline of algorithms for creating a multimedia summary of popular events. I will conclude by discussing my current and future work around creating and applying AI algorithms to: (a) gain insights about county-level COVID-19 vaccine concerns, (b) detect, reduce, and mitigate misinformation in text and online forums, and (c) understand the expression and evolution of bias (expressed in text) over time.
Anietie Andy is a senior data scientist at Penn Medicine Center for Digital Health. His research focuses on developing and applying natural language processing and machine learning algorithms to health care, public health, and well-being. Also, he is interested in developing natural language processing and machine learning algorithms that use multimodal sources (text, video, images) to summarize and gain insights about events and online communities.
talk: Forward & Inverse Causal Inference in a Tensor Framework, 1-2 pm ET, 3/29
Forward and Inverse Causal Inference in a Tensor Framework
M. Alex O. Vasilescu Institute of Pure and Applied Mathematics, UCLA
Developing causal explanations for correct results or for failures from mathematical equations and data is important in developing a trustworthy artificial intelligence, and retaining public trust. Causal explanations are germane to the “right to an explanation” statute, i.e., to data-driven decisions, such as those that rely on images. Computer graphics and computer vision problems, also known as forward and inverse imaging problems, have been cast as causal inference questions consistent with Donald Rubin’s quantitative definition of causality, where “A causes B” means “the effect of A is B”, a measurable and experimentally repeatable quantity. Computer graphics may be viewed as addressing analogous questions to forward causal inference that addresses the “what if” question, and estimates a change in effects given a delta change in a causal factor. Computer vision may be viewed as addressing analogous questions to inverse causal inference that addresses the “why” question which we define as the estimation of causes given a forward causal model, and a set of observations that constrain the solution set. Tensor algebra is a suitable and transparent framework for modeling the mechanism that generates observed data. Tensor-based data analysis, also known in the literature as structural equation modeling with multimode latent variables, has been employed in representing the causal factor structure of data formation in econometrics, psychometric, and chemometrics since the 1960s. More recently, tensor factor analysis has been successfully employed to represent cause-and-effect in computer vision, and computer graphics, or for prediction and dimensionality reduction in machine learning tasks.
M. Alex O. Vasilescu received her education at the Massachusetts Institute of Technology and the University of Toronto. She is currently a senior fellow at UCLA’s Institute of Pure and Applied mathematics (IPAM) that has held research scientist positions at the MIT Media Lab from 2005-07 and at New York University’s Courant Institute of Mathematical Sciences from 2001-05. Vasilescu introduced the tensor paradigm for computer vision, computer graphics, and machine learning. She addressed causal inferencing questions by framing computer graphics and computer vision as multilinear problems. Causal inferencing in a tensor framework facilitates the analysis, recognition, synthesis, and interpretability of data. The development of the tensor framework has been spearheaded with premier papers, such as Human Motion Signatures (2001), TensorFaces (2002), Multilinear Independent Component Analysis (2005), TensorTextures (2004), and Multilinear Projection for Recognition (2007, 2011). Vasilescu’s face recognition research, known as TensorFaces, has been funded by the TSWG, the Department of Defenses Combating Terrorism Support Program, Intelligence Advanced Research Projects Activity (IARPA), and NSF. Her work was featured on the cover of Computer World and in articles in the New York Times, Washington Times, etc. MIT’s Technology Review Magazine named her to their TR100 list of honorees, and the National Academy of Science co-awarded the Keck Futures Initiative Grant.
talk: Machine Learning: New Methodology for Physical & Social Sciences, 1pm ET 3/24
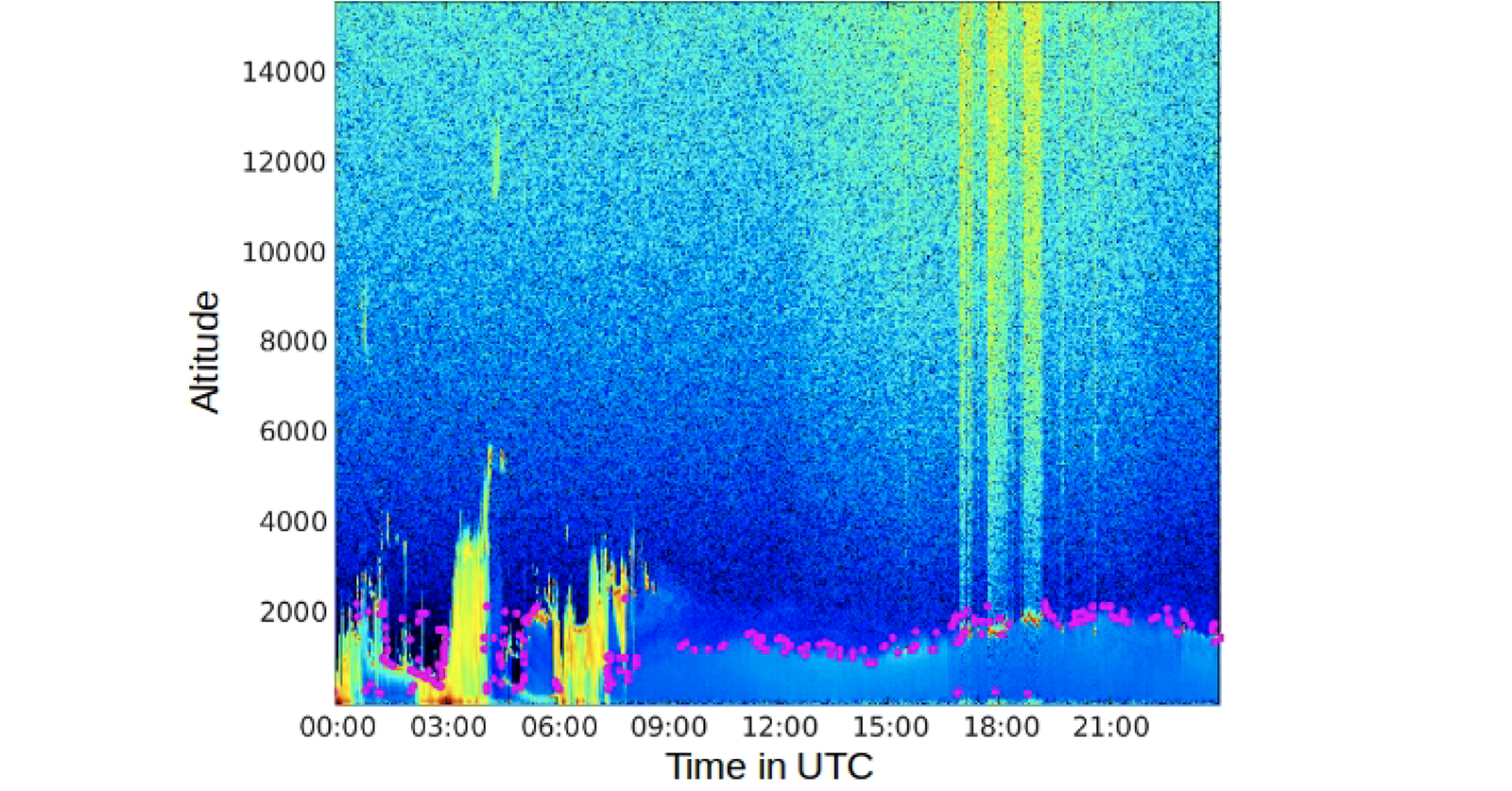
24 hour LIDAR backscatter profiles and PBLH points generated from image machine learning system
The Infusion of Machine Learning as a New Methodology for the Physical and Social Sciences
Dr. Jennifer Sleeman CSEE, UMBC
1:00-2:00 pm ET, Wednesday, March 24 Online via WebEx
Machine learning has made improvements in many areas of computing. Recently attention has been given to infusing social science methodology with machine learning. In addition, the physical sciences have begun to embrace machine learning to augment their physical parameterization and to discover new features in their computations. I will describe my work that relates to these new emerging areas of research. I will first describe our machine learning research efforts related to understanding the changing role of climate and its effects on society. I will describe how this methodology was also applied to understanding cyber-related exploits. As part of this work, I developed an expertise in generative modeling, which led to a patent in generative and translation-based methods applied to imagery. These ideas were fundamental to a contribution in machine learning using quantum annealing. Quantum computing holds promise for deep learning to reach model convergence faster than classical computers. I will describe work related to developing a new hybrid method that overcame qubit limitations for image generation.
In addition, I will describe my current work related to machine learning for the Physical Sciences. As part of a multi-disciplinary team from UMBC and other universities, my current work explores ways to augment and replace existing physical parameterizations with neural network based models. I have led a research effort to calculate the planetary boundary layer’s height (PBLH) used for ceilometer-based backscatter profiles and satellite-borne lidar instruments. This work addresses the largest uncertainty in climate change, namely the role of aerosols (dust, carbon, sulfates, sea salt, etc.). We employ a novel method that includes a deep segmentation neural network that uses near-time continuous profiles forming an image to determine boundary layer heights. This method overcomes limitations in wavelet approaches which are unable to identify the PBLH under certain conditions. I will also give a preview of two efforts related to Long Short Term Memory (LSTM) neural networks related to learning PBLH changes over time. These research efforts result from collaborations with two students in the UMBC CSEE department and are being published and presented at the AAAI 2021 Spring Symposium on Combining Artificial Intelligence and Machine Learning with Physics Sciences.
Dr. Jennifer Sleeman is a Research Assistant Professor in Computer Science at the University of Maryland, Baltimore County (UMBC). Her research interests include generative models, natural language processing, semantic representation, image generation, and deep learning. Dr. Sleeman received the prestigious recognition of being a 2019 EECS Rising Star. She was also recognized in 2017 as one of the best Data Scientists in the Washington, DC region by DCFemTech. She defended her Ph.D. thesis, Dynamic Data Assimilation for Topic Modeling (DDATM) in 2017 under Tim Finin and Milton Halem. Her thesis-related work was awarded a Microsoft “AI for Earth” resource grant in 2017 and 2018 and also won the best paper award in the Semantic Web for Social Good Workshop presented at International Semantic Web Conference in 2018. She was an invited guest panelist at the AI for Social Good AAAI Fall Symposium in 2019 and was also an invited keynote speaker at the Sixth IEEE International Conference on Data Science and Engineering (ICDSE 2020), where she presented her ideas related to AI for Social Good and Science. She is an active research scientist in generative deep learning methods for which she holds a patent. She has over 12 years of machine learning experience and over 22 years of software engineering experience, in both academic and government/industry settings. She is currently funded by NASA and NOAA (PI). She also teaches Introduction to Artificial Intelligence at the University of Maryland, Baltimore County (UMBC) and currently mentors two Master’s students
talk: (Don’t) Mind the Gap: Bridging the Worlds of People and IoT Devices, 1-2 ET 3/23
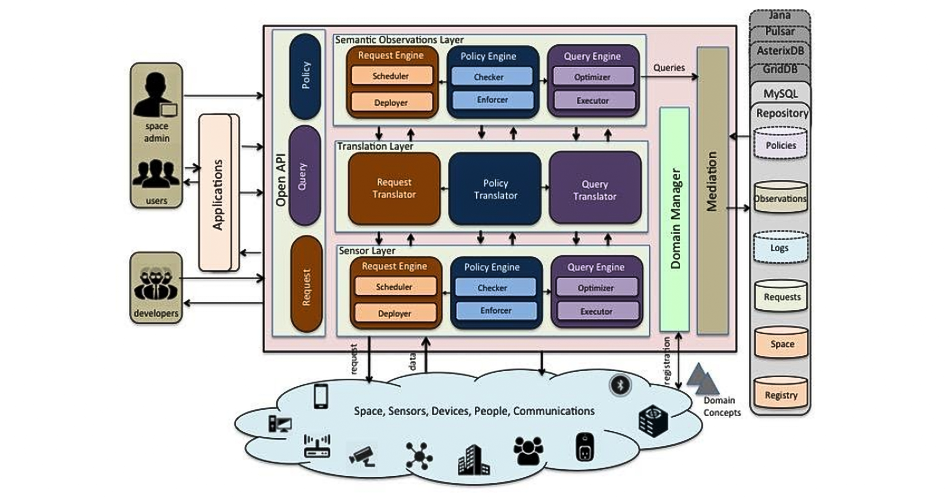
TIPPERS is an IoT data management middleware system developed at UCI that manages IoT smart spaces by collecting sensor data, inferring semantically meaningful information, and providing developers with data for intelligent applications.
(Don’t) Mind the Gap: Bridging the Worlds of People and IoT Devices
1:00-2:00 pm ET, Tuesday, 23 March 2021 online via WebEx
The Internet of Things (IoT) has the potential to improve our lives through different services given the diversity of smart devices and their capabilities. For example, the IoT can empower services to make the re-opening of business during the current pandemic safer by monitoring adherence to regulations. But the large amounts of highly heterogeneous data captured by IoT devices typically require further processing to become useful information. The challenge is thus for IoT systems to determine which sensor data has to be captured/stored/processed/shared to, for instance, determine the occupancy of a specific office building or the spaces in which a potential exposure took place. This becomes even more challenging when IoT systems have to take into account the privacy preferences of individuals, such as the need to prevent sharing data about their daily patterns or habits.
In this talk, I will discuss my efforts into helping IoT systems bridge the gap between the world of IoT devices and the world where people act. First, I will introduce a model to represent knowledge about sensors/actuators, people, spaces, events, and their relationships. Based on the model, I will explain an algorithmic solution to translate user requests and privacy preferences defined in a high-level, more semantically meaningful way into operations on IoT devices and their captured data. Second, I will talk about the enforcement of privacy preferences in the context of the IoT. Finally, I will overview my experience building and deploying an IoT data management system, TIPPERS, which has been deployed at UC Irvine and two US Navy vessels and is soon to be deployed on other campuses. I will conclude the talk by discussing the exciting future work opportunities towards supporting the next generation of ubiquitous IoT data management systems and technologies that autonomously, transparently, and at scale, balance the trade-off between providing users with high utility and respecting people’s privacy requirements.
Roberto Yus is a Postdoctoral Researcher in the Computer Science department at the University of California, Irvine working with Prof. Sharad Mehrotra. Before that, he spent a year as a visiting researcher at the University of Maryland, Baltimore County working with Prof. Anupam Joshi and Prof. Tim Finin. He obtained his Ph.D. in Computer Science from the University of Zaragoza, Spain, funded through a 4-year fellowship from the Spanish Ministry of Science and Innovation. His research interests are in the fields of data management, knowledge representation, privacy, and the Internet of Things (IoT). His research focuses on the design of semantic data management solutions to empower IoT systems to understand user information requirements and user privacy preferences and adapt their operations taking those into account. Roberto’s research has been published in top-tier conferences and journals such as VLDB and the Journal of Web Semantics. He is part of the editorial board of the “Sensors” and “Frontiers in Big Data” journals and has served as part of the organizing and program committee of several conferences and workshops in addition to serving as an external reviewer for multiple conferences and journals.
talk: Towards Contextual Security of AI-enabled platforms, 1-2 pm ET 3/22
Towards Contextual Security of AI-enabled platforms
Dr. Nidhi Rastogi Rensselaer Polytechnic Institute
The explosive growth of Internet-connected and AI-enabled devices and data produced by them has introduced significant threats. For example, malware intrusions (SolarWinds) have become perilous and extremely hard to discover, while data breaches continue to compromise user privacy (Zoom credentials exposed) and endanger personally identifiable information. My research takes a holistic approach towards systems and platforms to address security-related concerns using contextual and explainable models.
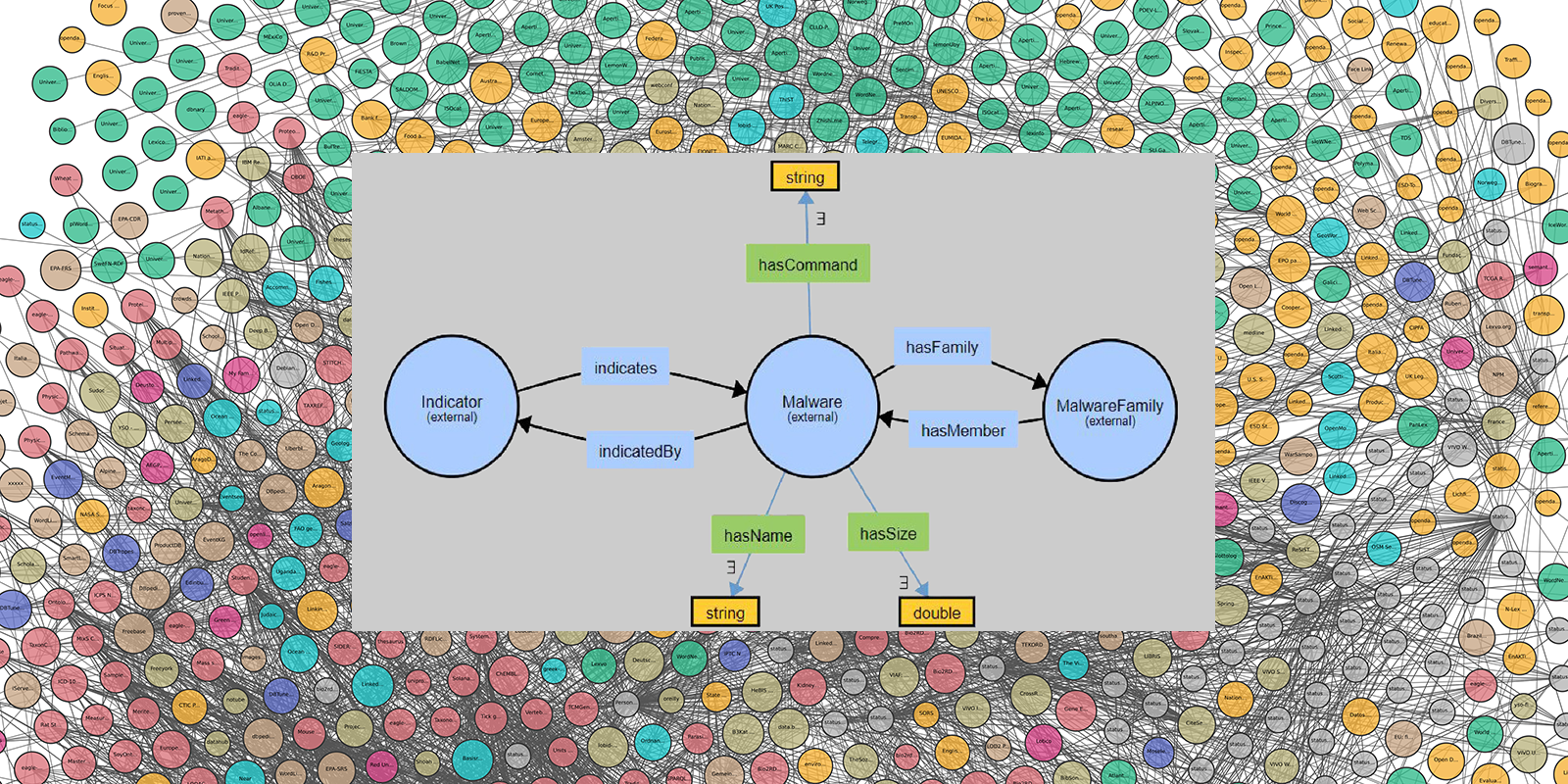
In this talk, I will present ongoing work that analyzes and improves the cybersecurity posture of Internet-connected systems and devices using automated, trustworthy, and contextual AI-models. Specifically, my research in malware threat intelligence gathers diverse information from varied datasets – system and network logs, source code, and text. In [1], an open-source ontology (MALOnt) contextualizes threat intelligence by aggregating malware-related information into classes and relations. TINKER [2, 3] – the first open-source malware knowledge graph, instantiates MALOnt classes and enables information extraction, reasoning, analysis, detection, classification, and cyber threat attribution. At present, the research is addressing the trustworthiness of information sources and extractors.
1. Rastogi, N., Dutta, S., Zaki, M. J., Gittens, A., & Aggarwal, C. (2020). MALOnt: An ontology for malware threat intelligence, In KDD’20 Workshop at International workshop on deployable machine learning for security defense. Springer, Cham.
2. Rastogi, N., Dutta, S., Christian, R., Gridley, J., Zaki, M. J., Gittens, A., and Aggarwal, C. (2021). Knowledge graph generation and completion for contextual malware threat intelligence. In USENIX Security’21, Accepted.
3. Yee, D., Dutta, S., Rastogi, N., Gu, C., and Ma, Q. (2021). TINKER: Knowledge graph for threat intelligence. In ACL-IJCNLP’21, Under Review.
Dr. Nidhi Rastogi is a Research Scientist at Rensselaer Polytechnic Institute. Her research is at the intersection of cybersecurity, artificial intelligence, large-scale networks, graph analytics, and data privacy. She has papers accepted at top venues such as USENIX, TrustCom, ISWC, Wireless Telecommunication Symposium, and Journal of Information Policy. For the past two years, Dr. Rastogi has been the lead PI for three cybersecurity, privacy research projects and a contributor to one healthcare AI project. For her contributions to cybersecurity and encouraging women in STEM, Dr. Rastogi was recognized in 2020 as an International Women in Cybersecurity by the Cyber Risk Research Institute. She was a speaker at the SANS cybersecurity summit and the Grace Hopper Conference. Dr. Rastogi is the co-chair for DYNAMICS workshop (2020-) and has served as a committee member for DYNAMICS’19, IEEE S&P’16 (student PC), invited reviewer for IEEE Transactions on Information Forensics and Cybersecurity (2018,19), FADEx laureate for the 1st French-American Program on Cyber-Physical Systems’16, Board Member (N2Women 2018-20), and Feature Editor for ACM XRDS Magazine (2015-17). Before her Ph.D. from RPI, Dr. Rastogi also worked in the industry on heterogeneous wireless networks (cellular, 802.1x, 802.11) and network security through engineering and research positions at Verizon and GE Global Research Center, and GE Power. She has interned at IBM Zurich, BBN Raytheon, GE GRC, and Yahoo, which provides her a quintessential perspective in applied industrial research and engineering.
talk: Theoryful Machine Learning in the Chemical Sciences, 1-2 Fri 2/5
Theoryful Machine Learning in the Chemical Sciences
Modern machine learning (ML) algorithms have achieved remarkable success in “theoryless” problems of image recognition and natural language processing. When these algorithms find applications in “theoryful” domains like physical sciences, they frequently benefit from the incorporation of domain knowledge into the ML architecture, whether enforcing constraints or symmetries or interpreting neural networks as physical systems.
The chemical sciences have many “theoryful” ML problems. In this talk, I will discuss three projects in which we leverage background theory when designing and adopting ML algorithms. In the first project, we use classical thermodynamics to derive a method to characterize mixture properties in molecular simulations and show that multiple linear regression (with no bias) is the formally correct and thermodynamically consistent model for fitting and predicting these properties. We recently developed an alternative proof from statistical thermodynamics that gives the same result, and we provide evidence that nonlinear methods provide no improvement in performance. In the second project, we perform high-throughput molecular simulations of adsorption (when molecules from a gas or liquid stick on the surface or in the pores of a material), which we analyze using neural networks. We derive a correspondence between theories of multicomponent adsorption and the self-attention mechanism in the transformer architecture and show how the theory-inspired architecture has improved generalization over the multilayer perceptron.
In the final project, I will share work on symbolic regression, in collaboration with the Mathematics of AI department at IBM. In symbolic regression, given a data set, a search through some “space of possible equations” identifies accurately-fitting and parsimonious equations that can be easily inspected by humans. We formulate the symbolic regression problem as a mixed-integer nonlinear programming (MINLP) problem and use MINLP solvers to systematically solve multiple functional forms at once, instead of via the traditional approaches that use genetic algorithms. Future approaches to integrate symbolic regression with chemical theory will be discussed.
Tyler R. Josephson is an Assistant Professor in the Chemical, Biochemical, and Environmental Engineering department at the University of Maryland, Baltimore County. He received his B.S. in Chemical Engineering from the University of Minnesota in 2011, and his Ph.D. in Chemical Engineering from the University of Delaware in 2017, after which he was a postdoctoral associate in the University of Minnesota Chemistry Department. Prof. Josephson uses multi-scale modeling and machine learning to study catalysis, solvation, adsorption, and phase equilibria. During his downtime, he loves learning new things, thinking about deep topics (like science and philosophy), and playing the piano.
Visiting Prof. Ed Raff’s forthcoming book: Inside Deep Learning
Visiting Prof. Ed Raff’s forthcoming book Inside Deep Learning
Congratulation to Dr. Edward Raff for his forthcoming book Inside Deep Learning being published by Manning. The first three chapters are now available free online via Manning’s Early Access Program, with more to come. Dr. Raff is a Chief Scientist at Booz Allen Hamilton and both an alumnus of and visiting assistant professor in the UMBC CSEE department.
He describes the target audience for his book as “the middle between “give me a tool” and ‘CS/Stats/ML Ph.D. graduate book’ that gives utility and understanding.” He gives thanks to his UMBC students in his Computer Science and Data Science classes who have been “guinea pigs for this book/course material.”
Here’s how the publisher describes the book: “Inside Deep Learning is a fast-paced beginners guide to solving common technical problems with deep learning. Written for everyday developers, there are no complex mathematical proofs or unnecessary academic theory. You’ll learn how deep learning works through plain language, annotated code, and equations as you work through dozens of instantly useful PyTorch examples. As you go, you’ll build a French-English translator that works on the same principles as professional machine translation and discover cutting-edge techniques just emerging from the latest research. Best of all, every deep learning solution in this book can run in less than fifteen minutes using free GPU hardware!”
Ed Raff received a Ph.D. in Computer Science in 2018 with a dissertation on “Malware Detection and Cyber Security via Compression.” He is currently a Chief Scientist at Booz Allen Hamilton. He has done research on deep learning, malware detection, reproducibility in machine learning, detecting fairness and bias in machine learning models and data analytics, and high-performance computing. He has also been a visiting Assistant Professor at UMBC since 2018 and taught in both the Computer Science and Data Science programs. Dr. Raff has over 40 peer-reviewed publications, three best paper awards, and has presented at many major conferences.
talk: Medical Informatics – Promise and Barriers Towards Precise Medicine, 10am ET Mon 11/23, Webex
The challenging time facing the pandemic forced us to relate to the human being’s broadband picture and his surrounding as one functioning system across countries and continents. The need is to relate both to the Micro (including in-body, physical, and mental conditions) and the Macro (such as environmental, cultural, and economic factors) providing a comprehensive understanding of the human body functioning in the surrounding, towards a precise, personalized “disease signature,” definition, especially these days. A systematic literature review on the “disease signature” term revealed no clear definition. In many articles, the “disease signature” phrase appears as a single biomarker (often genetic), mainly related to neurology or oncology. (Stemmer, A. at All, 2019. Journal of Molecular Neuroscience, 67(4)). The major goal is the unity of nature, science, and technology, from the nanoscale towards converging knowledge and tools, at a confluence of disciplines, as was envisioned by the NSF in 2001 (NBIC) and further at the joint EU-US WTEC effort “Converging of Knowledge, Technology, Society,” Roco et al., Springer 2013.
The COVID-19 global health emergency increased the need for early precise diagnosis and treatment while facing major physical and mental threat and stress, such as Post Traumatic Stress Disorder (PTSD). These understandings reemphasized the need to join all forces, converge, verify and embed all knowledge, expertise, and new advanced technologies in the various disciplines. Furthermore, it enforced to verify the data originated by various sources while bridging all cultural, conceptual, curation and technology barriers, preserving privacy and ethics regulations and ensuring reliable advanced analysis tools. All of the above provide profound insight into the human body and brain functioning in the surrounding and reliable “Disease Signature,” followed by suitable therapeutic treatment.
The question to be asked: Are we able to collect Big enough data, distributed and representative enough, while bridging all barriers and accurate analysis tools to ensure reliable, replicable, reproducible outcome towards precise, personalized medicine? The Brain Medical Informatics Platform (MIP), developed by the EU Human Brain Flagship Project, as part of the EBRAINS platform, is a key feasibility study along these lines. It involves broad clinical data collections from 30 hospitals, converging knowledge and data, embedding new technologies for data privacy, preservation, and curation, as well as sophisticated analysis tools. The MIP and EBRAINS framework goal is to identify “BRAIN Disease Signatures” towards reliable medical treatment. A 3C (Categorize, Classify, Cluster) Methodology, developed in our lab, is one of the tools available on the MIP. It incorporates expert medical knowledge and experience into the analysis process of disease manifestation and potential biomarkers towards reliable insights. The 3C approach was applied to the ADNI (Alzheimer’s disease Neuro Imaging) cohort, discovering association with new subtypes, which were later verified using the Rome Gemelli hospital labs clinical data. Other case studies were Parkinson’s Disease, genetic and biomarker research: (Tal Kozlovski, et al., 2019, Frontiers in Neurology, Movement Disorders), as well as PTSD research (Ben-Zion et al., 2020, Translational Psychiatry), both in collaboration with the Tel Aviv Medical Center. The COVID-19 global health emergency increased the need for early precise diagnosis and treatment while facing major physical and mental threat and stress, such as Post Traumatic Stress Disorder (PTSD). These understandings reemphasized the need to join all forces, converge, verify and embed all knowledge, expertise, and new advanced technologies in the various disciplines. Furthermore, it enforced to verify the data originated by various sources while bridging all cultural, conceptual, curation and technology barriers, preserving privacy and ethics regulations and ensuring reliable advanced analysis tools. All of the above to provide profound insight into the human body and brain functioning in the surrounding as well as reliable “Disease Signature”, followed by suitable therapeutic treatment.
Providing “Healthy Aging” to the elderly is a perfect example conceiving all, these days, as the elderly became one of the vulnerable groups at risk. The loneliness and isolation forced by the current pandemic results in severe conditions, including stress disorders and PTSD. Thus, an International “Healthy Aging” initiative was established at TAU, promoting broad interdisciplinary research, combining knowledge and data analysis as well as advanced technologies, from most areas of science: including economics, art, social sciences, mental and physical health, lifestyle, engineering, etc. All that to ensure the best fitted reliable treatment and a balanced quality of life to the elderly in general, and in these days, in particular.
Dr. Mira Marcus-Kalish is the Director of International Research Collaborations at Tel Aviv University. Her main areas of research are mathematical modeling, converging technologies, and data mining. Dr. Kalish holds a Ph.D. in Operations Research from the Technion, Israel Institute of Technology, where she developed one of the first computerized systems for electrocardiogram (ECG) diagnosis. Her postdoctoral training was at Harvard University, the MBCRR (Molecular Biology Computer Research and Resource) laboratory, and at the Dana Farber Cancer Institute. She was awarded her B.Sc. in Statistics and Biology from the Hebrew University of Jerusalem
CSEE alum Balaji Vishwanathan’s robotics company featured in Forbes
Balaji Vishwanathan, CEO of Invento Robotics, with Mitra, its flagship robot. Image: Hemant Mishra for Forbes India
Balaji Vishwanathan (MS ’07) startup company Invento Robotics is featured in Forbes India magazine
Balaji Viswanathan started his career at Microsoft, and moved from there to develop startups in such diverse areas as robotics, education, and finance. He has embraced the true calling of an entrepreneur, using long term goals to develop companies that actively seek to make a global impact. This is exemplified by his Bengaluru-based company, Invento Robotics, which is currently using its humanoid robots to provide a myriad of services, from taking temperatures to collecting patient information to bringing medications and food to patients in isolation wards, in an effort to fight COVID-19.
His business was featured in Forbes India magazine as part of a series on companies that have pivoted to use technology to address the Covid-19 pandemic. The article discusses how Invento has applied its first mobile robot models, Mitra, to perform tasks like collecting patient details, checking temperatures, and setting up video calls with doctors. Two new models, C-Astra and Robodoc have now been deployed to disinfect rooms and virtually interact with patients inside Covid-19 wards.
Balaji has recently returned to UMBC as a part-time Ph.D. student in the Computer Science program and will work on research topics that will advance the state of the art in supporting intelligent robotics.
New NSF grant to improve human-robot interaction
Professor Ferraro in UMBC’s Pi2 visualization laboratory talking to a virtual robot.
CSEE faculty receive NSF award to helprobots learn tasks by interacting naturally with people
This project will enable robots to learn to perform tasks with human teammates from language and other modalities, and then transfer what they have learned to other robots with different capabilities in order to perform different tasks. This will ultimately allow human-robot teaming in domains where people use varied language and instructions to complete complex tasks. As robots become more capable and ubiquitous, they are increasingly moving into complex, human-centric environments such as workplaces and homes.
Being able to deploy useful robots in settings where human specialists are stretched thin, such as assistive technology, elder care, and education, has the potential to have far-reaching impacts on human quality of life. Achieving this will require the development of robots that learn, from natural interaction, about an end user’s goals and environment.
This work is intended to make robots more accessible and usable for non-specialists. In order to verify success and involve the broader community, tasks will be drawn from and tested in community Makerspaces, which are strongly linked with both education and community involvement. It will address how collaborative learning and successful performance during human-robot interactions can be accomplished by learning from and acting on grounded language. To accomplish this, the project will revolve around learning structured representations of abstract knowledge with goal-directed task completion, grounded in a physical context.
There are three high-level research thrusts: leverage grounded language learning from many sources, capture and represent the expectations implied by language, and use deep hierarchical reinforcement learning to transfer learned knowledge to related tasks and skills. In the first, new perceptual models to learn an alignment among a robot’s multiple, heterogeneous sensor and data streams will be developed. In the second, synchronous grounded language models will be developed to better capture both general linguistic and implicit contextual expectations that are needed for completing shared tasks. In the third, a deep reinforcement learning framework will be developed that can leverage the advances achieved by the first two thrusts, allowing the development of techniques for learning conceptual knowledge. Taken together, these advances will allow an agent to achieve domain adaptation, improve its behaviors in new environments, and transfer conceptual knowledge among robotic agents.
The research award will support both faculty and students working in the Interactive Robotics and Language lab on this task. It includes an education and outreach plan designed to increase participation by and retention of women and underrepresented minorities (URM) in robotics and computing, engaging with UMBC’s large URM population and world-class programs in this area.
This site uses functional cookies and external scripts to improve your experience.
Privacy settings
Privacy Settings and Information
This site uses functional cookies and external scripts to improve your experience. Which cookies and scripts are used and how they impact your visit is specified on the left. Your choices will not impact your visit.
Details
NOTE: Third-party Google scripts on this website may have access to cross-site third-party cookies under the google.com domain. We, the CSEE Department, do not access, read, or write these third-party cookies, and as a result, we do not control their presence on your browser. You may block them by using a third-party cookie blocker in your browser.
If you click Accept below to accept the general cookie consent, then a “wpgdprc-consent” cookie will be stored on your browser, to record your general consent.
If you click Accept below to accept the general cookie consent, and also have Google Analytics cookies enabled (on the sidebar to the left), the CSEE Department website will store and access Google Analytics cookies on your browser. We use the data from these cookies to collect information on website usage statistics and improve user experience. If you do not wish to allow Google Analytics cookies on your browser, then either do not click Accept on the bottom bar, or disable Google Analytics on the left.
If you log in to this website, then several Wordpress cookies and session variables will be stored on your browser. Accessing the login screen constitutes your consent to have Wordpress cookies and session variables stored on your computer.
External Scripts
The CSEE Department website makes use of several external scripts to improve user experience. These include, but are not necessarily limited to: Google Calendar, Google Analytics, and ReCAPTCHA. If you choose to use this website, then you agree to allow these scripts to be loaded and executed.
External Links
Our service may contain links to other sites. If you click on a third-party link, you will be directed to that site. Note that these external sites are not operated by us. Therefore, we strongly advise you to review the Privacy Policy of these websites. We have no control over, and assume no responsibility for the content, privacy policies, or practices of any third-party sites or services.
NOTE: These settings will only apply to the browser and device you are currently using.