Release 8.1.5
A68003-01
Library |
Product |
Contents |
Index |
| Oracle8i Application Developer's Guide - Fundamentals Release 8.1.5 A68003-01 |
|
![]()
![]()
In Oracle8i, the SQL data definition language (DDL) commands have been enhanced to support creation of object types and the SQL data manipulation language (DML) commands have been enhanced to manipulate objects. Also, Oracle's application programming environments have been enhanced to support objects. These environments include the Oracle Call Interface (OCI), Pro*C/C++, Oracle Objects for OLE, and Java. For each of these environments, an overview of object enhancements is provided.
This chapter covers the following topics:
OCI is a set of C library functions that applications can use to manipulate data and schemas in an Oracle database. OCI supports both the associative style and the navigational style of data access.
|
See Also: Oracle Call Interface Programmer's Guide for more information about using objects with OCI. |
Traditionally, 3GL programs have manipulated data stored in a relational database using the associative style of access. In associative access, data is manipulated by executing SQL statements and PL/SQL procedures, which allows applications to utilize the benefits of the SQL and PL/SQL languages. Also, in associative access, data may be manipulated on the server without incurring the cost of transporting the data to the client(s). OCI supports associative access to objects by providing an API for executing SQL statements that manipulate object data. Specifically, OCI supports the following object capabilities for associative access:
REFs), and collections as input variables in SQL statements
REFs, and collections as output of SQL statement fetches
REFs, and collections
OCI also supports navigational access by object-oriented programs. In the object-oriented programming paradigm, applications model their real-world entities as a set of inter-related objects that form graphs of objects. The relationships between objects are implemented as references. An application processes objects by starting at some initial set of objects, using the references in these initial objects to traverse the remaining objects, and performing computations on each object. This style of access to objects is known as navigational access to objects. OCI provides an API for navigational access to objects. Specifically, OCI supports the following object capabilities for navigational access:
To support high-performance navigational access of objects, OCI runtime provides an object cache for caching objects in memory. The object cache supports references (REFs) to database objects in the object cache, the database objects can be identified (that is, pinned) through their references. Applications do not need to provide for allocation or freeing of memory when database objects are loaded into the cache, because the object cache provides transparent and efficient memory management for database objects.
Also, when database objects are loaded into the cache, they are transparently mapped into the host language representation. For example, in the C programming language, the database object is mapped to its corresponding C structure. The object cache maintains the association between the object copy in the cache and the corresponding database object. Upon transaction commit, changes made to the object copy in the cache are propagated automatically to the database.
The object cache maintains a fast look-up table for mapping REFs to objects. When an application de-references a REF and the corresponding object is not yet cached in the object cache, the object cache automatically sends a request to the server to fetch the object from the database and load it into the object cache. Subsequent de-references of the same REF are faster because they become local cache access and do not incur network round-trips. To notify the object cache that an application is accessing an object in the cache, the application pins the object; when it is finished with the object, it unpins it. The object cache maintains a pin count for each object in the cache. The count is incremented upon a pin call and decremented upon an unpin call. When the pin count goes to zero, it means the object is no longer needed by the application. The object cache uses a least-recently used (LRU) algorithm to manage the size of the cache. When the cache reaches the maximum size, the LRU algorithm frees candidate objects with a pin count of zero.
When you build an OCI program that manipulates objects, you must complete the following general steps:
For example, to manipulate instances of the object types in a C program, you must represent these types in the C host language format. You can do this by representing the object types as C structs. You can use a tool provided by Oracle called the Object Type Translator (OTT) to generate the C mapping of the object types. The OTT puts the equivalent C structs in header (*.h) files. You include these *.h files in the *.c files containing the C functions that implement the application.
The following sections introduce tips and techniques for using OCI effectively by walking through common operations performed by an OCI program that uses objects.
To enable object manipulation, the OCI program must be initialized in object mode. The following OCI code initializes a program in object mode:
err = OCIInitialize(OCI_OBJECT, 0, 0, 0, 0);
When the program is initialized in object mode, the object cache is initialized. Memory for the cache is not allocated at this time; instead, it is allocated only on demand.
You can control the size of the object cache by using the following two OCI environment handle attributes:
OCI_ATTR_CACHE_MAX_SIZE controls the maximum cache size
OCI_ATTR_CACHE_OPT_SIZE controls the optimal cache size
You can get or set these OCI attributes using the OCIAttrGet() or OCIAttrSet() functions. Whenever memory is allocated in the cache, a check is made to determine whether the maximum cache size has been reached. If the maximum cache size has been reached, the cache automatically frees (ages out) the least-recently used objects with a pin count of zero. The cache continues freeing such objects until memory usage in the cache reaches the optimal size, or until it runs out of objects eligible for freeing. The object cache does not limit cache growth to the maximum cache size. The servicing of the memory allocation request could cause the cache to grow beyond the specified maximum cache size. The above two parameters allow the application to control the frequency of object aging from the cache.
Pinning is the process of retrieving an object from the server to the client cache, laying it in memory, providing a pointer to it for an application to manipulate, and marking the object as being in use. The OCIObjectPin() function de-references the given REF and pins the corresponding object in the cache. A pointer to the pinned object is returned to the caller and this pointer is valid as long as the object is pinned in the cache. This pointer should not be used after the object is unpinned because the object may have aged out and therefore may no longer be in the object cache.
The following are examples of OCIObjectPin() and OCIObjectUnpin() calls:
status = OCIObjectPin(envh, errh, empRef,(OCIComplexObject*)0, OCI_PIN_RECENT, OCI_DURATION_TRANSACTION, OCI_LOCK_NONE, (dvoid**)&emp); /* manipulate emp object */ status = OCIObjectUnpin(envh, errh, emp);
The empRef parameter passed in the pin call specifies the REF to the desired employee object. A pointer to the employee object in the cache is returned via the emp parameter.
You can use the OCIObjectPinArray() function to pin an array of objects in one call. This function de-references an array of REFs and pins the corresponding objects in the cache. Objects that are not already cached in the cache are retrieved from the server in one network round-trip. Therefore, calling OCIObjectPinArray() to pin an array of objects improves application performance. Also, the array of objects you are pinning can be of different types.
When pinning an object, you can use the pin option argument to specify whether the recent version, latest version, or any version of the object is desired. The valid options are explained in more detail in the following list:
OCI_PIN_RECENT pin option instructs the object cache to return the object that is loaded into the cache in the current transaction; in other words, if the object was loaded prior to the current transaction, the object cache needs to refresh it with the latest version from the database. Succeeding pins of the object within the same transaction would return the cached copy and would not result in database access. In most cases, you should use this pin option.
OCI_PIN_LATEST pin option instructs the object cache to always get the latest copy of the object. If the object is already in the cache and not-locked, the object copy is refreshed with the latest copy from the database. On the other hand, if the object in the cache is locked, Oracle assumes that it is the latest copy, and the cached copy is returned. You should use this option for applications that must display the most recent copy of the object, such as applications that display stock quotes, current account balance, etc.
OCI_PIN_ANY pin option instructs the object cache to fetch the object in the most efficient manner; the version of the returned object does not matter. The pin any option is appropriate for objects which do not change often, such as product information, parts information, etc. The pin any option also is appropriate for read-only objects.
When pinning an object, you can specify the duration for which the object is pinned in the cache. When the duration expires, the object is unpinned automatically from the cache. The application should not use the object pointer after the object's pin duration has ended. An object can be unpinned prior to the expiration of its duration by explicitly calling the OCIObjectUnpin() function. Oracle supports two pre-defined pin durations:
OCI_DURATION_SESSION) lifetime is the duration of the database connection. Objects that are required in the cache at all times across transactions should be pinned with session duration.
OCI_DURATION_TRANS) lifetime is the duration of the database transaction. That is, the duration ends when the transaction is rolled back or committed.
When pinning an object, the caller can specify whether the object should be locked via lock options. When an object is locked, a server-side lock is acquired, which prevents any other user from modifying the object. The lock is released when the transaction commits or rolls back. The following list describes the available lock options:
OCI_LOCK_NONE lock option instructs the cache to pin the object without locking.
OCI_LOCK_X lock option instructs the cache to pin the object only after acquiring a lock. If the object is currently locked by another user, the pin call with this option waits until it can acquire the lock before returning to the caller. Using the OCI_LOCK_X lock option is equivalent to executing a SELECT FOR UPDATE statement.
OCI_LOCK_X_NOWAIT lock option instructs the cache to pin the object only after acquiring a lock. Unlike the OCI_LOCK_X option, the pin call with OCI_LOCK_X_NOWAIT option will not wait if the object is currently locked by another user. Using the OCI_LOCK_X_NOWAIT lock option is equivalent to executing a SELECT FOR UPDATE WITH NOWAIT statement.
Complex Object Retrieval (COR) can significantly improve the performance of applications that manipulate graphs of objects. COR allows applications to pre-fetch a set of related objects in one network round-trip, thereby improving performance. When pinning the root object(s) using OCIObjectPin() or OCIObjectPinArray(), you can specify the related objects to be pre-fetched along with the root. The pre-fetched objects are not pinned in the cache; instead, they are put in the LRU list. Subsequent pin calls on these objects result in a cache hit, thereby avoiding a round-trip to the server.
The application specifies the set of related objects to be pre-fetched by providing the following information:
REF to the root object
REF attributes should be de-referenced and which resulting object should be pre-fetched. The depth defines the boundary of objects pre-fetched. The depth level is the shortest number of references that need to be traversed from the root object to a related object.
For example, consider a purchase order system with the following properties:
REF to a customer object, and a collection of REFs that point to line item objects.
Suppose you want to calculate the total cost of a particular purchase order. To maximize efficiency, you want to fetch only the objects necessary for the calculation from the server to the client cache, and you want to fetch these objects with the least number of calls to the server possible.
If you do not use COR, your application must make several server calls to retrieve all of the necessary objects. However, if you use COR, you can specify the objects that you want to retrieve and exclude other objects that are not required. To calculate the total cost of a purchase order, you need the purchase order object, the related line item objects, and the related stock item objects, but you do not need the customer objects.
Therefore, as shown in Figure 19-1, COR enables you to retrieve the required information for the calculation in the most efficient way possible. When pinning the purchase order object without COR, only that object is retrieved. When pinning it with COR, the purchase order and the related line item objects and stock item objects are retrieved. However, the related customer object is not retrieved because it is not required for the calculation.
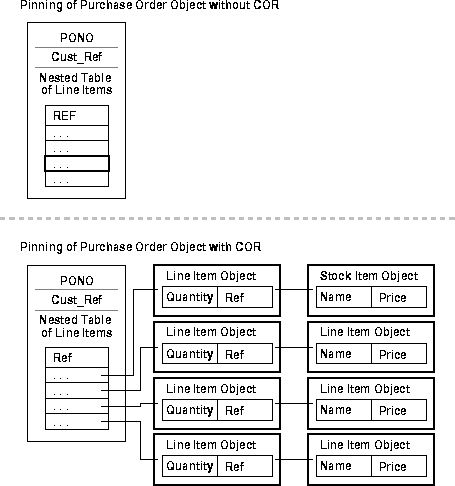
The OCIObjectNew() function creates transient or persistent objects. A transient object's lifetime is the duration of the session in which it was created. A persistent object is an object that is stored in an object table in the database. The OCIObjectNew() function returns a pointer to the object created in the cache, and the application should initialize the new object by setting the attribute values directly. The object is not created in the database yet; it will be created and stored in the database when it is flushed from the cache.
When OCIObjectNew() creates an object in the cache, it sets all the attributes to NULL. The attribute null indicator information is recorded in the parallel null indicator structure. If the application sets the attribute values, but fails to set the null indicator information in the parallel null structure, then upon object flush the object attributes will be set to NULL in the database.
In Oracle8i, if you want to set all of the attributes to NOT NULL during object creation instead, you can use the OCI_OBJECT_NEW_NOTNULL attribute of the environment handle using the OCIAttrSet() function. When set, this attribute creates a non-null object. That is, all the attributes are set to default values provided by Oracle and their null status information in the parallel null indicator structure is set to NOT NULL. Using this attribute eliminates the additional step of changing the indicator structure. You cannot change the default values provided by Oracle. Instead, you can populate the object with your own default values immediately after object creation.
When OCIObjectNew() is used to create a persistent object, the caller must identify the database table into which the newly created object is to be inserted. The caller identifies the table using a table object. Given the schema name and table name, the OCIObjectPinTable() function returns a pointer to the table object. Each call to OCIObjectPinTable() results in a call to the server to fetch the table object information. The call to the server happens even if the required table object has been previously pinned in the cache. When the application is creating multiple objects to be inserted into the same database table, Oracle Corporation recommends that the table object be pinned once and the pointer to the table object be saved for future use. Doing so improves performance of the application.
Before you can update an object, the object must be pinned in the cache. After pinning the object, the application can update the desired attributes directly. You must make a call to the OCIObjectMarkUpdate() function to indicate that the object has been updated. Objects which have been marked as updated are placed in a dirty list and are flushed to the server upon cache flush or when the transaction is committed.
You can delete an object by calling the OCIObjectMarkDelete() function or the OCIObjectMarkDeleteByRef() function.
The object cache supports both a pessimistic locking scheme and an optimistic locking scheme.
In the pessimistic locking scheme, objects are locked up-front prior to modifying the object in the cache, ensuring that no other user can modify the object till the transaction owning the lock performs a commit or rollback. The object can be locked at the time of pin by choosing the appropriate locking options. An object which was not locked at the time of pin also can be locked by calling explicit lock function OCIObjectLock(). A new locking function, OCIObjectLockNoWait(), has been added in Oracle8i. As the name indicates, this function does not wait to acquire the lock if another user holds a lock on the object.
In the optimistic locking scheme, objects are fetched and modified in the cache without acquiring a lock. A lock is acquired only when the object is flushed to the server. Optimistic locking allows for a higher degree of concurrent access than pessimistic locking. To use optimistic locking effectively, the Oracle8i object cache has been enhanced to detect if an object is changed by any other user since it was fetched into the cache. By turning on the object change detection mode, object modifications are made persistent only if the object has not been changed by any other user since it was fetched into the cache. This mode is activated by setting OCI_OBJECT_DETECTCHANGE attribute of the environment handle using the OCIAttrSet() function.
Changes made to the objects in the object cache are not sent to the database until the object cache is flushed. The OCICacheFlush() function flushes all changes in a single network round-trip between the client and the server. The changes may involve insertion of new objects into the appropriate object tables, updating objects in object tables, and deletion of objects from object tables. If the application commits a transaction by calling the OCITransCommit() function, the object cache automatically performs a cache flush prior to committing the transaction.
For a demonstration of how to use OCI with Oracle objects, see the cdemocor1.c file in $ORACLE_HOME/rdbms/demo.
Pro*C/C++ support for objects mirrors the support provided by OCI. Extensions to the embedded SQL syntax provide both associative and navigational access to objects. The Object Type Translator is used to generate C language representations (structs) for database object types that are used as host variables in the embedded SQL statements. By extending the embedded SQL syntax, Pro*C/C++ users retain the benefits of precompile-time syntactic and semantic checking for their object-relational applications.
Pro*C/C++ offers the following capabilities for associative access to objects:
INSERT, UPDATE, and DELETE statements, or in the WHERE clause of a SELECT statement
SELECT and FETCH statements
DESCRIBE statement, to get the object's type and schema information
Object navigation is a new programming paradigm introduced in release 8.0 of Oracle. Pro*C/C++ offers the following capabilities to support a more object-oriented interface to objects:
OBJECT DEREF statement
OBJECT UPDATE, OBJECT DELETE, and OBJECT RELEASE statements
OBJECT CREATE statement
OBJECT FLUSH statement
The C representation for objects that is generated by the Oracle Type Translator (OTT) uses opaque OCI types such as OCIString and OCINumber for scalar attributes. Collection types and object references are similarly represented using OCITable, OCIArray, and OCIRef types. While using opaque types insulates the application developer from changes to the internal format of these types, using such types in a C or C++ application is cumbersome. Pro*C/C++ provides the following ease-of-use enhancements to simplify use of OCI types in C and C++ applications:
OBJECT GET statement.
OBJECT SET statement.
COLLECTION GET statement. Furthermore, if the collection is comprised of scalar types, then the OCI types can be implicitly converted to a compatible C type.
COLLECTION SET statement. As with the COLLECTION GET statement, if the collection is comprised of scalar types, C types are implicitly converted to OCI types.
Oracle Objects for OLE (OO4O) provides full support for accessing and manipulating instances of REFs, value instances, variable-length arrays (VARRAYs), and nested tables in an Oracle database server.
Figure 19-2 illustrates the containment hierarchy for value instances of all types in OO4O.
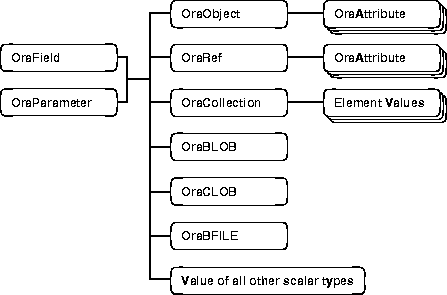
Instances of these types can be fetched from the database or passed as input or output variables to SQL statements and PL/SQL blocks, including stored procedures and functions. All instances are mapped to COM Automation Interfaces that provide methods for dynamic attribute access and manipulation. These interfaces may be obtained from:
REF)
The OraObject interface is a representation of an Oracle embedded object or a value instance. It contains a collection interface (OraAttributes) for accessing and manipulating (updating and inserting) individual attributes of a value instance. Individual attributes of an OraAttributes collection interface can be accessed by using a subscript or the name of the attribute.
The following Visual Basic example illustrates how to access attributes of the Address object in the person_tab table:
Set Person = OraDatabase.CreateDynaset("select * from person_tab", 0&) set Address = Person.Fields("Addr").Value msgbox Address.Zip msgbox.Address.City
The OraRef interface represents an Oracle object reference (REF) as well as referenceable objects in client applications. The object attributes are accessed in the same manner as attributes of an object represented by the OraObject interface. OraRef is derived from an OraObject interface via the containment mechanism in COM. REF objects are updated and deleted independent of the context they originated from, such as Dynasets. The OraRef interface also encapsulates the functionality for navigating through graphs of objects utilizing the Complex Object Retrieval Capability (COR) in OCI, described in "Using Complex Object Retrieval (COR)".
The OraCollection interface provides methods for accessing and manipulating Oracle collection types, namely variable-length arrays (VARRAYs) and nested tables in OO4O. Elements contained in a collection are accessed by subscripts.
The following Visual Basic example illustrates how to access attributes of the EnameList object from the department table:
Set Person = OraDatabase.CreateDynaset("select * from department", 0&) set EnameList = Department.Fields("Enames").Value 'access all elements of the EnameList VArray for I=1 to I=EnameList.Size msgbox EnameList(I) Next I
Java has emerged as a powerful, modern object-oriented language that provides developers with a simple, efficient, portable, and safe application development platform. Oracle provides two ways to integrate Oracle object features with Java: JDBC and Oracle SQLJ. The following sections provide more information about JDBC and Oracle SQLJ.
Oracle provides tight integration between its Oracle object features and its JDBC functionality. You can map SQL types to Java classes, and Oracle offers considerable flexibility in how this mapping is done.
Version 2.0 of the JDBC specification contains support for Object-Relational constructs, such as user-defined (Object) types. JDBC materializes Oracle objects as instances of particular Java classes. There are two main issues in using JDBC to access Oracle objects: creating the Java classes for the Oracle objects and populating these classes. You have the following options:
STRUCT. In this case, JDBC will create the classes for the attributes and populate them for you.
SQLData interface or the CustomDatum interface.
Oracle8i JDBC Developer's Guide and Reference for more information about JDBC access to Oracle object data.
See Also:
Oracle also provides Oracle SQLJ, a standard way to embed SQL statements in Java programs. Source files are then processed by Oracle SQLJ. When writing a SQLJ application, a user writes a Java program and embeds SQL statements in it, while following certain standard syntactic rules that govern how SQL statements can be embedded in Java programs. The user then runs the Oracle SQLJ translator, which converts this SQLJ program to a standard Java program, and replaces the embedded SQL statements with calls to the Oracle SQLJ runtime. The generated Java program is compiled, using any Java compiler, and run against a database. The Oracle SQLJ runtime environment consists of a thin SQLJ runtime library, which is implemented in pure Java, and which implements your SQL operations, typically using a JDBC driver.
SQLJ, therefore, is similar to the ANSI/ISO Embedded SQL standards, which prescribe how static SQL is embedded in C/C++, COBOL, FORTRAN, and other languages. For example, Oracle's pre-compiler product, Pro*C/C++, is an implementation of the Embedded SQL standard in the C/C++ host language. The following are the general steps required for writing and running an Oracle SQLJ program:
#sql token.
Usually, the Oracle SQLJ translator performs steps 2, 3, and 4 automatically, invoking a Java compiler and profile customizer in the process. At translation time, the static SQL statements in the program can be checked against a given database schema. The Oracle SQLJ runtime uses a JDBC driver, typically the Oracle JDBC driver, in accessing the database.
Oracle SQLJ supports either strongly typed or weakly typed Java representations of object types, reference types (REFs), and collection types (VARRAYs and nested tables) to be used in iterators or host expressions. Strongly typed representations use a custom Java class that corresponds to a particular object type, reference type, or collection type and must implement the interface oracle.sql.CustomDatum. This paradigm is supported by the Oracle JPublisher utility, which can be used to automatically generate such custom Java classes. Weakly typed representations use the class oracle.sql.STRUCT (for objects), oracle.sql.REF (for references), or oracle.sql.ARRAY (for collections).
To use Oracle-specific object, reference, and collection types, you must customize your profile appropriately. The default Oracle customizer, oracle.sqlj.runtime.util.OraCustomizer, typically is recommended. This customization is performed automatically when you run the sqlj script unless you specify otherwise.
For Oracle-specific semantics checking, you must use an appropriate checker. The default checker, oracle.sqlj.checker.OracleChecker, is recommended. This acts as a front-end and chooses an appropriate checker for you, depending on whether you enable online checking and on which JDBC driver and Oracle database release you use.
|
See Also: This section only provides an overview of support for objects in Oracle SQLJ. For detailed information about using objects in Oracle SQLJ, see the Oracle8i SQLJ Developer's Guide and Reference |
Custom Java classes are used by the JDBC driver to convert data between the database and your Java application, and they make the data accessible. You should provide custom Java classes for all user-defined types that you use in an Oracle SQLJ application. Even if you do not directly use custom Java class instances in your code, the JDBC driver can use such instances in order to convert data. Using custom Java classes is more convenient and less prone to error than using the weakly typed classes oracle.sql.STRUCT, REF, and ARRAY. Custom Java classes are first-class types that you can use to read from and write to user-defined SQL types transparently.
Oracle provides the interface oracle.sql.CustomDatum and the related interface oracle.sql.CustomDatumFactory as vehicles to use in mapping Oracle object types, reference types, and collection types to custom Java classes and in converting data between the database and your application. Custom Java classes must implement CustomDatum in order to be used in Oracle SQLJ iterators and host expressions.
Data passed to or from the database is in the form of an oracle.sql.Datum object, with the underlying data being in the format of the appropriate oracle.sql.Datum subclass, such as oracle.sql.STRUCT. This data is still in its codified database format; the oracle.sql.Datum object is just a wrapper.
The CustomDatum interface specifies a toDatum() method for data conversion from Java format to database format. This method takes as input your OracleConnection object (which is required by the Oracle JDBC drivers) and converts data to the appropriate oracle.sql.* representation. The OracleConnection object is necessary so that the JDBC driver can perform appropriate type checking and type conversions at runtime. The following is the CustomDatum and toDatum() specification:
interface oracle.sql.CustomDatum { oracle.sql.Datum toDatum(OracleConnection c); }
The CustomDatumFactory interface specifies a create() method that constructs instances of your custom Java class, converting from database format to Java format. This method takes as input a Datum object containing data from the database and an integer indicating the SQL type of the underlying data, such as OracleTypes.RAW. It returns an object of your custom Java class, which implements the CustomDatum interface. This object receives its data from the Datum object that was input. The following is the CustomDatumFactory and create() specification:
interface oracle.sql.CustomDatumFactory { oracle.sql.CustomDatum create(oracle.sql.Datum d, int sqlType); }
To complete the relationship between the CustomDatum and CustomDatumFactory interfaces, there is a requirement for a static getFactory() method that you must implement in any custom Java class that implements the CustomDatum interface. This method returns an object that implements the CustomDatumFactory interface, and that therefore can be used to create instances of your custom Java class. This returned object may itself be an instance of your custom Java class, and its create() method is used by the Oracle JDBC driver to produce further instances of your custom Java class as necessary.
Custom Java classes produced by JPublisher automatically implement the CustomDatum and CustomDatumFactory interfaces and the getFactory() method.
|
See Also:
Oracle8i SQLJ Developer's Guide and Reference for more information about the |
You can implement methods of Oracle objects as wrappers in custom Java classes. Whether the underlying stored procedure is written in PL/SQL or is written in Java and published to SQL is invisible to the user.
A Java wrapper method that is used to invoke a server method requires a connection in order to communicate with the server. The connection object can be provided as an explicit parameter, or can be associated in some other way (as an attribute of your custom Java class, for example).
You can write each wrapper method as an instance method of the custom Java class, regardless of whether the server method that the wrapper method invokes is an instance method or a static method. Custom Java classes generated by JPublisher use this technique.
There are also issues regarding output and input-output parameters in methods of Oracle objects. In the database, if a stored procedure (Oracle object method) modifies the internal state of one of its arguments, the actual argument that was passed to the stored procedure is modified. In Java this is not possible. When a JDBC output parameter is returned from a stored procedure call, it is stored in a newly created object. The original object identity is lost.
One way to return an output or input-output parameter to the caller is to pass the parameter as an element of an array. If the parameter is input-output, the wrapper method takes the array element as input; after processing, the wrapper assigns the output to the array element. Custom Java classes generated by JPublisher use this technique--each output or input-output parameter is passed in a one-element array.
You can include the .java files for your custom Java classes on the Oracle SQLJ command line together with your .sqlj file. For example, if ObjectDemo.sqlj uses the Oracle object types Address and Person, and you have run JPublisher or otherwise produced custom Java classes for these objects, you can run Oracle SQLJ in the following way:
sqlj options ObjectDemo.sqlj Address.java AddressRef.java Person.java PersonRef.java
Otherwise you can compile them separately, using your Java compiler directly. If you do this, it must be done prior to translating the .sqlj file.
Oracle offers flexibility in how you can customize the mapping of Oracle object types, reference types, and collection types to Java classes in a strongly typed paradigm. You have the following choices in creating these custom Java classes:
Although you have the option of manually coding your custom Java classes, it is recommended that you use JPublisher. If you need special functionality, you can subclass the classes that JPublisher creates and modify the subclasses as necessary.
When you run JPublisher for a user-defined object type, it automatically creates the following:
This class includes getter and setter methods for each attribute. The method names are of the form getFoo() and setFoo() for attribute foo.
Also, you can optionally instruct JPublisher to generate wrapper methods in your class that invoke the associated Oracle object methods executing in the server.
This class includes a getValue() method that returns an instance of your custom object class, and a setValue() method that updates an object value in the database, taking as input an instance of the custom object class.
When you run JPublisher for a user-defined collection type, it automatically creates the following:
This class includes overloaded getArray() and setArray() methods to retrieve or update a collection as a whole, a getElement() method and setElement() method to retrieve or update individual elements of a collection, and additional utility methods.
JPublisher-produced custom Java classes in any of these categories implement the CustomDatum interface, the CustomDatumFactory interface, and the getFactory() method.
Oracle SQLJ is flexible in how it allows you to use host variables and iterators in reading or writing object data through strongly typed objects or references.
For iterators, you can use custom object classes as iterator column types. Alternatively, you can have iterator columns that correspond to individual object attributes (similar to extent tables), using column types that appropriately map to the attribute datatypes in the database.
For host expressions, you can use host variables of your custom object class type or custom reference class type, or you can use host variables that correspond to object attributes, using variable types that appropriately map to the attribute datatypes in the database.
|
See Also: Oracle8i SQLJ Developer's Guide and Reference for more information about how to manipulate Oracle objects using custom object classes, custom object class attributes, and custom reference classes for host variables and iterator columns in Oracle SQLJ executable statements. |
Weakly typed objects, references, and collections are supported by Oracle SQLJ. Their general use is not recommended and there are some restrictions on their use, but in some circumstances they may be useful. For example, you may have generic code that can use "any STRUCT" or "any REF" (although if this code uses dynamic SQL it would require coding in JDBC instead of Oracle SQLJ).
In using Oracle objects, references, or collections in an Oracle SQLJ application, you have the option of using generic and weakly typed oracle.sql classes instead of the strongly typed custom Java classes that implement the CustomDatum interface.
The following oracle.sql classes can be used for iterator columns or host expressions in Oracle SQLJ:
In host expressions they are supported as follows:
Using these classes is not generally recommended, however, as you would lose all the advantages of the strongly typed paradigm that Oracle SQLJ offers.
Each attribute in a STRUCT object or each element in an ARRAY object is stored in an oracle.sql.Datum object, with the underlying data in the form of the appropriate oracle.sql.* type (such as oracle.sql.NUMBER or oracle.sql.CHAR). Attributes in a STRUCT object are nameless.
Because of the generic nature of the STRUCT and ARRAY classes, Oracle SQLJ can do no type checking where objects or collections are written to or read from instances of these classes.
Oracle Corporation recommends that you use custom Java classes for objects, references, and collections, preferably classes produced by JPublisher.
A weakly typed object (STRUCT instance), reference (REF instance), or collection (ARRAY instance) cannot be used in host expressions in the following circumstances:
OUT or INOUT parameter in stored procedure or function call
OUT parameter in stored function result-expression
There are no Oracle SQLJ restrictions on their use in IN host expressions; however, there may be JDBC requirements to initialize weakly typed STRUCT, REF, and ARRAY objects with a SQL typecode from oracle.jdbc.driver.OracleTypes.