Release 8.1.5
A67775-01
Library |
Product |
Contents |
Index |
| Oracle8i Tuning Release 8.1.5 A67775-01 |
|
![]()
![]()
Structured Query Language (SQL) is used to perform all database operations, although some Oracle tools and applications simplify or mask its use. This chapter provides an overview of the issues involved in tuning database operations from the SQL point-of-view:
For more information about tuning PL/SQL statements, please refer to the PL/SQL User's Guide and Reference.
See Also:
This section introduces:
Always approach the tuning of database operations from the standpoint of the particular goals of your application. Are you tuning serial SQL statements or parallel operations? Do you have an online transaction processing (OLTP) application, or a data warehousing application?
As a result, these two divergent types of applications have contrasting goals for tuning as described in Table 4-1.
| Tuning Situation | Goal |
|---|---|
|
Serial SQL Statement |
Minimize resource use by the operation. |
|
Parallel Operations |
Maximize throughput for the hardware. |
The goal of tuning one SQL statement in isolation can be stated as:
Minimize resource use by the operation being performed.
You can experiment with alternative SQL syntax without actually modifying your application. To do this, use the EXPLAIN PLAN command with the alternative statement that you are considering and compare the alternative statement's execution plan and cost with that of the existing one. The cost of a SQL statement appears in the POSITION column of the first row generated by EXPLAIN PLAN. However, you must run the application to see which statement can actually be executed more quickly.
The goal of tuning parallel execution can be stated as:
Maximize throughput for the given hardware.
If you have a powerful system and a massive, high-priority SQL statement to run, parallelize the statement so it use all available resources.
Oracle can perform the following operations in parallel:
Look for opportunities to parallelize operations in the following situations:
Whenever an operation you are performing in the database takes a long elapsed time, whether it is a query or a batch job, you may be able to reduce the elapsed time by using parallel operations.
You can split rows so they are not all accessed by a single process.
|
See Also:
Chapter 26, "Tuning Parallel Execution" and Oracle8i Concepts, for basic principles of parallel execution. |
Tuning OLTP applications mostly involves tuning serial SQL statements. You should consider two design issues: use of SQL and shared PL/SQL, and use of different transaction modes.
|
See Also:
Information on tuning data warehouse applications appears in Chapter 11, "Optimizing Data Warehouse Applications". |
To minimize parsing, use bind variables in SQL statements within OLTP applications. In this way all users can share the same SQL statements while using fewer resources for parsing.
Sophisticated users can use discrete transactions if performance is of the utmost importance, and if the users are willing to design the application accordingly.
Serializable transactions can be used if the application must be ANSI compatible. Because of the overhead inherent in serializable transactions, Oracle strongly recommends the use of read-committed transactions instead.
If excessive use of triggers degrades system performance, modify the conditions under which triggers fire by executing the CREATE TRIGGER or REPLACE TRIGGER commands. You can also turn off triggers with the ALTER TRIGGER command.
Whether you are writing new SQL statements or tuning problematic statements in an existing application, your methodology for tuning database operations essentially concerns CPU and disk I/O resources.
Focus your tuning efforts on statements where the benefit of tuning demonstrably exceeds the cost of tuning. Use tools such as TKPROF, the SQL Trace Facility, and Oracle Trace to find the problem statements and stored procedures. Alternatively, you can query the V$SORT_USAGE view to see the session and SQL statement associated with a temporary segment.
The statements with the most potential to improve performance, if tuned, include:
In the V$SQLAREA view you can find those statements still in the cache that have done a great deal of disk I/O and buffer gets. (Buffer gets show approximately the amount of CPU resource used.)
|
See Also:
Chapter 14, "The SQL Trace Facility and TKPROF", Chapter 15, "Using Oracle Trace", and Oracle8i Reference for more information about dynamic performance views. |
Remember that application design is fundamental to performance. No amount of SQL statement tuning can make up for inefficient application design. If you encounter SQL statement tuning problems, perhaps you need to change the application design.
You can use two strategies to reduce the resources consumed by a particular statement:
Statements may use more resources because they do the most work, or because they perform their work inefficiently--or they may do both. However, the lower the resource used per unit of work (per row processed), the more likely it is that you can significantly reduce resources used only by changing the application itself. That is, rather than changing the SQL, it may be more effective to have the application process fewer rows, or process the same rows less frequently.
These two approaches are not mutually exclusive. The former is clearly less expensive, because you should be able to accomplish it either without program change (by changing index structures) or by changing only the SQL statement itself rather than the surrounding logic.
This section describes five ways you can improve SQL statement efficiency:
Restructuring the indexes is a good starting point, because it has more impact on the application than does restructuring the statement or the data.
Do not use indexes as a panacea. Application developers sometimes think that performance will improve if they just write enough indexes. If a single programmer creates an appropriate index, this might indeed improve the application's performance. However, if 50 programmers each create an index, application performance will probably be hampered!
After restructuring the indexes, you can try restructuring the statement. Rewriting an inefficient SQL statement is often easier than repairing it. If you understand the purpose of a given statement, you may be able to quickly and easily write a new statement that meets the requirement.
Because SQL is a flexible language, more than one SQL statement may meet the needs of your application. Although two SQL statements may produce the same result, Oracle may process one faster than the other. You can use the results of the EXPLAIN PLAN statement to compare the execution plans and costs of the two statements and determine which is more efficient.
This example shows the execution plans for two SQL statements that perform the same function. Both statements return all the departments in the DEPT table that have no employees in the EMP table. Each statement searches the EMP table with a subquery. Assume there is an index, DEPTNO_INDEX, on the DEPTNO column of the EMP table.
This is the first statement and its execution plan:
SELECT dname, deptno FROM dept WHERE deptno NOT IN (SELECT deptno FROM emp);
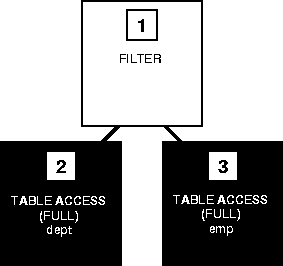
Step 3 of the output indicates that Oracle executes this statement by performing a full table scan of the EMP table despite the index on the DEPTNO column. This full table scan can be a time-consuming operation. Oracle does not use the index because the subquery that searches the EMP table does not have a WHERE clause that makes the index available.
However, this SQL statement selects the same rows by accessing the index:
SELECT dname, deptno FROM dept WHERE NOT EXISTS (SELECT deptno FROM emp WHERE dept.deptno = emp.deptno);
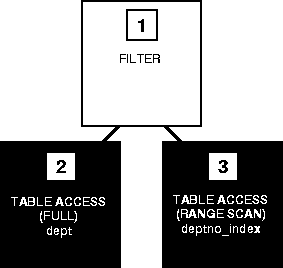
|
See Also:
The optimizer chapter in Oracle8i Concepts for more information on interpreting execution plans. |
The WHERE clause of the subquery refers to the DEPTNO column of the EMP table, so the index DEPTNO_INDEX is used. The use of the index is reflected in Step 3 of the execution plan. The index range scan of DEPTNO_INDEX takes less time than the full scan of the EMP table in the first statement. Furthermore, the first query performs one full scan of the EMP table for every DEPTNO in the DEPT table. For these reasons, the second SQL statement is faster than the first.
If you have statements in your applications that use the NOT IN operator, as the first query in this example does, you should consider rewriting them so that they use the NOT EXISTS operator. This would allow such statements to use an index, if one exists.
Use equijoins. Without exception, statements that perform equijoins on untransformed column values are the easiest to tune.
Join order can have a significant effect on performance. The main objective of SQL tuning is to avoid performing unnecessary work to access rows that do not affect the result. This leads to three general rules:
The following example shows how to tune join order effectively:
SELECT info FROM taba a, tabb b, tabc c WHERE a.acol between :alow and :ahigh AND b.bcol between :blow and :bhigh AND c.ccol between :clow and :chigh AND a.key1 = b.key1 AMD a.key2 = c.key2;
The first three conditions in the example above are filter conditions applying to only a single table each. The last two conditions are join conditions.
Filter conditions dominate the choice of driving table and index. In general, the driving table should be the one containing the filter condition that eliminates the highest percentage of the table. Thus, if the range of :alow to :ahigh is narrow compared with the range of acol, but the ranges of :b* and :c* are relatively large, then taba should be the driving table, all else being equal.
Once you know your driving table, choose the most selective index available to drive into that table. Alternatively, choose a full table scan if that would be more efficient. From there, the joins should all happen through the join indexes, the indexes on the primary or foreign keys used to connect that table to an earlier table in the join tree. Rarely should you use the indexes on the non-join conditions, except for the driving table. Thus, once taba is chosen as the driving table, you should use the indexes on b.key1 and c.key2 to drive into tabb and tabc, respectively.
The work of the following join can be reduced by first joining to the table with the best still-unused filter. Thus, if "bcol between ..." is more restrictive (rejects a higher percentage of the rows seen) than "ccol between ...", the last join can be made easier (with fewer rows) if tabb is joined before tabc.
Use untransformed column values. For example, use:
WHERE a.order_no = b.order_no
Rather than:
WHERE TO_NUMBER (substr(a.order_no, instr(b.order_no, '.') - 1) = TO_NUMBER (substr(a.order_no, instr(b.order_no, '.') - 1)
Do not use SQL functions in predicate clauses or WHERE clauses. The use of an aggregate function, especially in a subquery, often indicates that you could have held a derived value on a master record.
Avoid mixed-mode expressions, and beware of implicit type conversions. When you want to use an index on the VARCHAR2 column charcol, but the WHERE clause looks like this:
AND charcol = <numexpr>
Where numexpr is an expression of number type (for example, 1, USERENV('SESSIONID'), numcol, numcol+0,...), Oracle will translate that expression into:
AND to_number(charcol) = numexpr
This has the following consequences:
You can avoid this problem by replacing the top expression with the explicit conversion:
AND charcol = to_char(<numexpr>)
Alternatively, make all type conversions explicit. The statement:
numcol = charexpr
allows use of an index on numcol because the default conversion is always character-to-number. This behavior, however, is subject to change. Making type conversions explicit also makes it clear that charexpr should always translate to a number.
SQL is not a procedural language. Using one piece of SQL to do many different things is not a good idea: it usually results in a less-than-optimal result for each task. If you want SQL to accomplish different things, then write two different statements rather than writing one statement that will do different things depending on the parameters you give it.
Optimization (determining the execution plan) takes place before the database knows what values will be substituted into the query. An execution plan should not, therefore, depend on what those values are. For example:
SELECT info from tables WHERE ... AND somecolumn BETWEEN decode(:loval, 'ALL', somecolumn, :loval) AND decode(:hival, 'ALL', somecolumn, :hival);
Written as shown, the database cannot use an index on the somecolumn column because the expression involving that column uses the same column on both sides of the BETWEEN.
This is not a problem if there is some other highly selective, indexable condition you can use to access the driving table. Often, however, this is not the case. Frequently you may want to use an index on a condition like that shown, but need to know the values of :loval, and so on, in advance. With this information you can rule out the ALL case, which should not use the index.
If you want to use the index whenever real values are given for :loval and :hival (that is, if you expect narrow ranges, even ranges where :loval often equals :hival), you can rewrite the example in the following logically equivalent form:
SELECT /* change this half of union all if other half changes */ info FROM tables WHERE ... AND somecolumn between :loval and :hival AND (:hival != 'ALL' and :loval != 'ALL') UNION ALL SELECT /* Change this half of union all if other half changes. */ info FROM tables WHERE ... AND (:hival = 'ALL' OR :loval = 'ALL');
If you run EXPLAIN PLAN on the new query, you seem to obtain both a desirable and an undesirable execution plan. However, the first condition the database evaluates for either half of the UNION ALL will be the combined condition on whether :hival and :loval are ALL. The database evaluates this condition before actually getting any rows from the execution plan for that part of the query. When the condition comes back false for one part of the UNION ALL query, that part is not evaluated further. Only the part of the execution plan that is optimum for the values provided is actually carried out. Since the final conditions on :hival and :loval are guaranteed to be mutually exclusive, then only one half of the UNION ALL will actually return rows. (The ALL in UNION ALL is logically valid because of this exclusivity. It allows the plan to be carried out without an expensive sort to rule out duplicate rows for the two halves of the query.)
Use optimizer hints, such as /*+ORDERED */ to control access paths. This is a better approach than using traditional techniques or "tricks of the trade" such as CUST_NO + 0. For example, use
SELECT /*+ FULL(EMP) */ E.ENAME FROM EMP E WHERE E.JOB = 'CLERK';
rather than
SELECT E.ENAME FROM EMP E WHERE E.JOB || '' = 'CLERK';
|
See Also:
For more information on hints, please refer to Chapter 7, "Optimizer Modes, Plan Stability, and Hints". |
Remember that WHERE (NOT) EXISTS is a useful alternative.
Data value lists are normally a sign that an entity is missing. For example:
WHERE TRANSPORT IN ('BMW', 'CITROEN', 'FORD', HONDA')
The real objective in the WHERE clause above is to determine whether the mode of transport is an automobile, and not to identify a particular make. A reference table should be available in which transport type='AUTOMOBILE'.
Minimize the use of DISTINCT. DISTINCT always creates a SORT; all the data must be instantiated before your results can be returned.
When appropriate, use INSERT, UPDATE, or DELETE . . . RETURNING to select and modify data with a single call. This technique improves performance by reducing the number of calls to the database.
Be careful when joining views, when performing outer joins to views, and when you consider recycling views.
The shared SQL area in Oracle reduces the cost of parsing queries that reference views. In addition, optimizer improvements make the processing of predicates against views very efficient. Together these factors make possible the use of views for ad hoc queries. Despite this, joins to views are not recommended, particularly joins from one complex view to another.
The following example shows a query upon a column which is the result of a GROUP BY. The entire view is first instantiated, and then the query is run against the view data.
CREATE VIEW DX(deptno, dname, totsal) AS SELECT D.deptno, D.dname, E.sum(sal) FROM emp E, dept D WHERE E.deptno = D.deptno GROUP BY deptno, dname SELECT * FROM DX WHERE deptno=10;
An outer join to a multitable view can be problematic. For example, you may start with the usual emp and dept tables with indexes on e.empno, e.deptno, and d.deptno, and create the following view:
CREATE VIEW EMPDEPT (EMPNO, DEPTNO, ename, dname) AS SELECT E.EMPNO, E.DEPTNO, e.ename, d.dname FROM DEPT D, EMP E WHERE E.DEPTNO = D.DEPTNO(+);
You may then construct the simplest possible query to do an outer join into this view on an indexed column (e.deptno) of a table underlying the view:
SELECT e.ename, d.loc FROM dept d, empdept e WHERE d.deptno = e.deptno(+) AND d.deptno = 20;
The following execution plan results:
QUERY_PLAN -------------------------------------------- MERGE JOIN OUTER TABLE ACCESS BY ROWID DEPT INDEX UNIQUE SCAN DEPT_U1: DEPTNO FILTER VIEW EMPDEPT NESTED LOOPS OUTER TABLE ACCESS FULL EMP TABLE ACCESS BY ROWID DEPT INDEX UNIQUE SCAN DEPT_U1: DEPTNO
Until both tables of the view are joined, the optimizer does not know whether the view will generate a matching row. The optimizer must therefore generate all the rows of the view and perform a MERGE JOIN OUTER with all the rows returned from the rest of the query. This approach would be extremely inefficient if all you want is a few rows from a multitable view with at least one very large table.
To solve this problem is relatively easy, in the preceding example. The second reference to dept is not needed, so you can do an outer join straight to emp. In other cases, the join need not be an outer join. You can still use the view simply by getting rid of the (+) on the join into the view.
Beware of writing a view for one purpose and then using it for other purposes, to which it may be ill-suited. Consider this example:
SELECT dname from DX 7 WHERE deptno=10;
You can obtain dname and deptno directly from the DEPT table. It would be inefficient to obtain this information by querying the DX view (which was declared earlier in the present example). To answer the query, the view would perform a join of the DEPT and EMP tables, even though you do not need any data from the EMP table.
Using triggers consumes system resources. If you use too many triggers, you may find that performance is adversely affected and you may need to modify or disable them.
After restructuring the indexes and the statement, you can consider restructuring the data.
The overall purpose of any strategy for data distribution is to locate each data attribute such that its value makes the minimum number of network journeys. If the current number of journeys is excessive, then moving (migrating) the data is a natural solution.
Often, however, no single location of the data reduces the network load (or message transmission delays) to an acceptable level. In this case, consider either holding multiple copies (replicating the data) or holding different parts of the data in different places (partitioning the data).
Where distributed queries are necessary, it may be effective to code the required joins with procedures either in PL/SQL within a stored procedure, or within the user interface code.
When considering a cross-network join, you can either bring the data in from a remote node and perform the join locally, or you can perform the join remotely. The option you choose should be determined by the relative volume of data on the different nodes.
Once you have tuned your application's SQL statements, consider maintaining statistics with the useful procedures of the DBMS_STATS package. Also consider implementing Plan Stability features to maintain application performance characteristics despite system changes. Both of these topics are discussed in Chapter 7, "Optimizer Modes, Plan Stability, and Hints".