Release 8.1.5
A67775-01
Library |
Product |
Contents |
Index |
| Oracle8i Tuning Release 8.1.5 A67775-01 |
|
![]()
![]()
This chapter explains cost-based and rule-based optimization. It also describes how to use Plan Stability to preserve performance characteristics and to migrate to the cost-based optimizer. It also describes using hints to enhance Oracle performance. Topics in this chapter include:
Oracle8i Concepts for an introduction to the optimizer, access methods, join operations, and parallel execution.
See Also:
This section discusses:
This section also includes a brief discussion on:
In general, always use the cost-based optimization approach. The rule-based approach is available for the benefit of existing applications, but new optimizer functionality uses the cost-based approach.
The following features are available only with cost-based optimization.
The cost-based approach generally chooses an execution plan that is as good as or better than the plan chosen by the rule-based approach. This is specially true for large queries with multiple joins or multiple indexes. The cost-based approach also eliminates having to tune your SQL statements; this greatly improves productivity.
Use cost-based optimization for efficient star query performance. Similarly, use it with hash joins and histograms. Cost-based optimization is always used with parallel execution and with partitioned tables. To maintain the effectiveness of the cost-based optimizer, you must keep statistics current.
|
See Also:
For information on moving from the rule-based optimizer to the cost-based optimizer, refer to "Using Outlines to Move to the Cost-based Optimizer". |
To use cost-based optimization for a statement, collect statistics for the tables accessed by the statement and enable cost-based optimization using one of these methods:
The plans generated by the cost-based optimizer depend on the sizes of the tables. When using the cost-based optimizer with a small amount of data to test an application prototype, do not assume the plan chosen for the full-size database will be the same as that chosen for the prototype.
|
See Also:
For information on upgrading to more recent cost-based optimizer versions, please refer to "RDBMS Upgrades and the Cost-based Optimizer". |
The execution plan produced by the optimizer can vary depending upon the optimizer's goal. Optimizing for best throughput is more likely to result in a full table scan rather than an index scan, or a sort-merge join rather than a nested loops join. Optimizing for best response time, however, more likely results in an index scan or a nested loops join.
For example, consider a join statement that is executable with either a nested loops operation or a sort-merge operation. The sort-merge operation may return the entire query result faster, while the nested loops operation may return the first row faster. If your goal is to improve throughput, the optimizer is more likely to choose a sort-merge join. If your goal is to improve response time, the optimizer is more likely to choose a nested loops join.
Choose a goal for the optimizer based on the needs of your application:
By default, the cost-based approach optimizes for best throughput. You can change the goal of the cost-based approach in these ways:
Example: This statement changes the goal of the cost-based approach for your session to best response time:
ALTER SESSION SET OPTIMIZER_MODE = FIRST_ROWS;
For uniformly distributed data, the cost-based approach fairly accurately determines the cost of executing a particular statement. In such cases, the optimizer does not need histograms to estimate the cost of a query.
However, for nonuniformly distributed data, Oracle allows you to create histograms that describe data distribution patterns of a particular column. Oracle stores these histograms in the data dictionary for use by the cost-based optimizer.
Histograms are persistent objects, so you incur maintenance and space costs for using them. Compute histograms only for columns with highly skewed data distributions. The statistics that Oracle uses to build histograms, as well as all optimizer statistics, are static. If the data distribution of a column changes frequently, gather new histogram statistics for that column. Do this either explicitly, or by using the Automated Statistics Gathering feature as described.
Histograms are not useful for columns with these characteristics:
Create histograms on columns that are frequently used in WHERE clauses of queries and that have highly skewed data distributions. To do this, use the GATHER_TABLE_STATS procedure of the DBMS_STATS package. For example, to create a 10-bucket histogram on the SAL column of the EMP table, issue this statement:
EXECUTE DBMS_STATS.GATHER_TABLE_STATS ('scott','emp', METHOD_OPT => 'FOR COLUMNS SIZE 10 sal');
The SIZE keyword declares the maximum number of buckets for the histogram. You would create a histogram on the SAL column if there was an unusually high number of employees with the same salary and few employees with other salaries. You can also collect histograms for a single partition of a table.
Column statistics appear in the data dictionary views: USER_TAB_COLUMNS, ALL_TAB_COLUMNS, and DBA_TAB_COLUMNS.
Histograms appear in the data dictionary views USER_HISTOGRAMS, DBA_HISTOGRAMS, and ALL_HISTOGRAMS.
|
See Also:
For more information on the DBMS_STATS package, refer to "Gathering Statistics with the DBMS_STATS Package". For more information about the ANALYZE statement and its options, refer to the Oracle8i SQL Reference. |
The default number of buckets for a histogram is 75. This value provides an appropriate level of detail for most data distributions. However, since the number of buckets in the histogram, also referred to as 'the sampling rate', and the data distribution all affect a histogram's usefulness, you may need to experiment with different numbers of buckets to obtain optimal results.
If the number of frequently occurring distinct values in a column is relatively small, set the number of buckets to be greater than the number of frequently occurring distinct values.
You can find information about existing histograms in the database using these data dictionary views:
Find the number of buckets in each column's histogram in:
Oracle8i Reference for column descriptions of data dictionary views as well as histogram use and restrictions.
See Also:
Because the cost-based approach relies on statistics, generate statistics for all tables, clusters, and all types of indexes accessed by your SQL statements before using the cost-based approach. If the size and data distribution of these tables change frequently, generate these statistics regularly to ensure the statistics accurately represent the data in the tables.
Oracle can generate statistics using these techniques:
Because of the time and space required for computing table statistics, use estimation for tables and clusters rather than computation unless you need exact values. The reasons for this are:
To perform an exact computation, Oracle requires enough space to perform a scan and sort of the table. If there is not enough space in memory, temporary space may be required. For estimations, Oracle requires enough space to perform a scan and sort of all rows in the requested sample of the table. For indexes, computation does not take up as much time or space, so it is best to perform a full computation.
When you generate statistics for a table, column, or index, if the data dictionary already contains statistics for the analyzed object, Oracle updates the existing statistics. Oracle also invalidates any currently parsed SQL statements that access any of the analyzed objects.
The next time such a statement executes, the optimizer automatically chooses a new execution plan based on the new statistics. Distributed statements issued on remote databases that access the analyzed objects use the new statistics the next time Oracle parses them.
Some statistics are always computed, regardless of whether you specify computation or estimation. If you specify estimation and the time saved by estimating statistics is negligible, Oracle computes the statistics.
When you associate a statistics type with a column or domain index, Oracle calls the statistics collection method in the statistics type if you analyze the column or domain index.
|
See Also:
For more information about user-defined statistics, please refer to the Oracle8i Data Cartridge Developer's Guide. For more information about the ANALYZE statement, please refer to the Oracle8i SQL Reference. |
Gather statistics with the DBMS_STATS package as explained under the following heading.
DBMS_STATS provides the following procedures for gathering statistics:
Use the COMPUTE STATISTICS clause of the ANALYZE SQL statement to gather index statistics when creating or rebuilding an index. If you do not use the COMPUTE STATISTICS clause, or you have made major DML changes, use the GATHER_INDEX_STATS procedure to collect index statistics. The GATHER_INDEX_STATS procedure does not run in parallel. Using this procedure is equivalent to running:
ANALYZE INDEX [ownname.]indname [PARTITION partname] COMPUTE STATISTICS | ESTIMATE STATISTICS SAMPLE estimate_percent PERCENT
|
See Also:
For more information about the COMPUTE STATISTICS clause, please refer to the Oracle8i SQL Reference. |
This PL/SQL example gathers index statistics:
EXECUTE DBMS_STATS.GATHER_INDEX_STATS( 'scott','emp_idx');
The syntax and parameters for the GATHER_INDEX_STATS procedure are:
PROCEDURE GATHER_INDEX_STATS( ownname VARCHAR2, indname VARCHAR2, partname VARCHAR2 DEFAULT NULL, estimate_percent NUMBER DEFAULT NULL, stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL, statown VARCHAR2 DEFAULT NULL);
|
ownname |
Schema of the index to analyze. |
|
indname |
Name of index. |
|
partname |
Name of partition. |
|
estimate_percent |
Percentage of rows to estimate (NULL means "compute"). The valid range is [0.000001,100). |
|
stattab |
Name of a user statistics table into which Oracle should back up original statistics before collecting new statistics. For more information, please see the Oracle8i Supplied Packages Reference. |
|
statid |
Secondary identifier in stattab for backing up statistics. |
|
statown |
Schema where Oracle stores stattab if different from the location identified by the ownname parameter. |
After creating a table, use the GATHER_TABLE_STATS procedure to collect table, column, and index statistics as shown in the following example. The GATHER_TABLE_STATS procedure uses parallel processing for as much of the process as possible.
This PL/SQL example gathers table statistics:
EXECUTE DBMS_STATS.GATHER_TABLE_STATS ( 'scott','emp');
The syntax and parameters for the GATHER_TABLE_STATS procedure are:
PROCEDURE GATHER_TABLE_STATS ownname VARCHAR2, tabname VARCHAR2, partname VARCHAR2 DEFAULT NULL, estimate_percent NUMBER DEFAULT NULL, block_sample BOOLEAN DEFAULT FALSE, method_opt VARCHAR2 DEFAULT `FOR ALL COLUMNS SIZE 1', degree NUMBER DEFAULT NULL, granularity VARCHAR2 DEFAULT `DEFAULT', cascade BOOLEAN DEFAULT FALSE, stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL, statown VARCHAR2 DEFAULT NULL);
|
ownname |
Name of the schema of table to analyze. |
|
tabname |
Name of table. |
|
partname |
Name of partition. |
|
estimate_percent |
Percentage of rows to estimate (NULL means "compute"). The valid range is [0.000001,100). |
|
block_sample |
This value indicates whether to use random block sampling instead of the default random row sampling. Random block sampling is more efficient, but if the data is not randomly distributed on disk then the sample values may be somewhat correlated which may lead to less-than-accurate statistics. Only pertinent when estimating statistics. For more information about BLOCK_SAMPLE, please refer to Oracle8i Concepts. |
|
method_opt |
This value holds the options of the following format: (The phrase 'SIZE 1' (in other words, no histograms) is required to ensure gathering statistics in parallel): FOR ALL [INDEXED] COLUMNS [SIZE integer] FOR COLUMNS [SIZE integer] column|attribute [column|attribute...] Optimizer-related table statistics are always gathered. |
|
degree |
This value specifies the degree of parallelism (NULL means "use default table value"). |
|
granularity |
This value determines the granularity of statistics to collect (this only affects partitioned tables). PARTITION - Gather partition-level statistics. GLOBAL - Gather global statistics. SUBPARTITION - Gather subpartition level statistics. DEFAULT - Gather partition and global statistics. |
|
cascade |
Setting this parameter to TRUE gathers statistics on the indexes for this table. Index statistics are not gathered in parallel. Using this option is equivalent to running the GATHER_INDEX_STATS procedure on each of the table's indexes. The default value is FALSE due to the assumption that index statistics were recently gathered using the statement syntax 'CREATE INDEX... COMPUTE STATISTICS'. |
|
stattab |
Name of a user statistics table into which Oracle should back up original statistics before collecting new statistics. For more information on stattab and the following parameters, statid and statown, please refer to the Oracle8i Supplied Packages Reference. |
|
statid |
Secondary identifier in stattab for backing up statistics. |
|
statown |
Schema where Oracle stores stattab if different from the location identified by the ownname parameter. |
Run the GATHER_SCHEMA_STATS procedure to collect statistics for all objects in a schema as shown in the following example.
This PL/SQL example gathers schema statistics:
EXECUTE DBMS_STATS.GATHER_SCHEMA_STATS('scott');
The syntax and parameters for the GATHER_SCHEMA_STATS procedure are explained here. Oracle passes the values to all tables for all parameters shown.
PROCEDURE GATHER_SCHEMA_STATS( ownname VARCHAR2, estimate_percent NUMBER DEFAULT NULL, block_sample BOOLEAN DEFAULT FALSE, method_opt VARCHAR2 DEFAULT 'FOR ALL COLUMNS SIZE 1', degree NUMBER DEFAULT NULL, INSTANCES NUMBER DEFAULT NULL, granularity VARCHAR2 DEFAULT 'ALL', cascade BOOLEAN DEFAULT FALSE, stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL, options VARCHAR2 DEFAULT 'GATHER', objlist OUT OBJECTTAB, statown VARCHAR2 DEFAULT NULL);
|
ownname |
The name of the schema to analyze (NULL means "current user's schema"). |
|
estimate_percent |
The percentage of rows to estimate (NULL means "compute") The valid range is [0.000001,100). |
|
block_sample |
Indicates whether to use random block sampling instead of the default random row sampling. Random block sampling is more efficient, but if the data is not randomly distributed on disk then the sample values may be somewhat correlated which may lead to less-than-accurate statistics. Only pertinent when doing an estimate of statistics. |
|
method_opt |
Indicates the method options of the following format (the phrase 'SIZE 1' (in other words, no histograms) is required to enable gathering of statistics in parallel): FOR ALL [INDEXED] COLUMNS [SIZE integer]. |
|
degree |
Shows the degree of parallelism (NULL means "use table default value"). |
|
granularity |
Shows the granularity of statistics to collect. This only applies to partitioned tables. PARTITION - Gather partition-level statistics. GLOBAL - Gather global statistics. SUBPARTITION - Gather subpartition level statistics. DEFAULT - Gather partition and global statistics. |
|
cascade |
Shows to gather statistics on the indexes as well. Index statistics gathering will not be parallelized. Using this option is equivalent to running the GATHER_INDEX_STATS procedure on each of the indexes in the schema in addition to gathering table and column statistics. |
|
stattab |
Name of a user statistics table into which Oracle should back up original statistics before collecting new statistics. For more information, please see the Oracle8i Supplied Packages Reference. |
|
statid |
Secondary identifier in stattab for backing up statistics. For more information, please see the Oracle8i Supplied Packages Reference. |
|
options |
Please refer to the following section Automated Statistics Gathering. |
|
objlist |
Please refer to the following section Automated Statistics Gathering. |
|
statown |
Schema where Oracle stores stattab if different from the location identified by the ownname parameter. For more information, please see the Oracle8i Supplied Packages Reference. |
After creating your database, run the GATHER_DATABASE_STATS procedure to collect database statistics.
This PL/SQL example gathers database statistics:
EXECUTE DBMS_STATS.GATHER_DATABASE_STATS;
The syntax and parameters for the GATHER_DATABASE_STATS procedure are:
PROCEDURE GATHER_DATABASE_STATS( estimate_percent NUMBER DEFAULT NULL, block_sample BOOLEAN DEFAULT FALSE, method_opt VARCHAR2 DEFAULT `FOR ALL COLUMNS SIZE 1', degree NUMBER DEFAULT NULL, granularity VARCHAR2 DEFAULT, cascade BOOLEAN DEFAULT FALSE, stattab VARCHAR2 DEFAULT NULL, statid VARCHAR2 DEFAULT NULL, options VARCHAR2 DEFAULT 'GATHER', objlist OUT OBJECTTAB, statown VARCHAR2 DEFAULT NULL);
|
estimate_percent |
Shows the percentage of rows to estimate (NULL means "compute"). The valid range is [0.000001,100). |
|
block_sample |
Shows whether to use random block sampling instead of the default random row sampling. Random block sampling is more efficient, but if the data is not randomly distributed on disk then the sample values may be somewhat correlated which may lead to less-than-accurate statistics. Only applies when doing an estimate of statistics. |
|
method_opt |
Indicates the method options of the following format (the phrase 'SIZE 1' (in other words, no histograms) is required to enable gathering of statistics in parallel): FOR ALL [INDEXED] COLUMNS [SIZE integer]. |
|
degree |
Shows the degree of parallelism (NULL means "use table default value"). |
|
granularity |
Indicates the granularity of statistics to collect (applies only to partitioned tables). PARTITION - Gather partition-level statistics. GLOBAL - Gather global statistics. SUBPARTITION - Gather subpartition level statistics. DEFAULT - Gather partition and global statistics. |
|
cascade |
Setting this value to TRUE gathers statistics on the indexes as well. Index statistics gathering is not parallelized. Using this option is equivalent to running the GATHER_INDEX_STATS procedure on all indexes in the database in addition to gathering table and column statistics. |
|
stattab |
Name of a user statistics table into which Oracle should back up original statistics before collecting new statistics. For more information, please see the Oracle8i Supplied Packages Reference. |
|
statid |
Secondary identifier in stattab for backing up statistics. For more information, please see the Oracle8i Supplied Packages Reference. |
|
options |
Please refer to the following section "Automated Statistics Gathering". |
|
objlist |
Please refer to the following section "Automated Statistics Gathering". |
|
statown |
Schema where Oracle stores stattab if different from the location identified by the ownname parameter. For more information, please see the Oracle8i Supplied Packages Reference. |
Oracle recommends the following procedure for gathering new optimizer statistics for a particular schema.
Before gathering new statistics, use DBMS_STATS.EXPORT_SCHEMA_STATS to extract and save existing statistics. Then use DBMS_STATS.GATHER_SCHEMA_STATS to gather new statistics. You can implement both of these with a single call to the GATHER_SCHEMA_STATS procedure.
If key SQL statements experience significant performance degradation, either gather statistics again using a larger sample size, or perform these steps:
You may want to use the new statistics if they result in improved performance for the majority of SQL statements, and if the number of problem SQL statements is small. In this case, do the following:
This feature allows you to automatically gather statistics. You can also use it to create lists of tables that have stale statistics or to create lists of tables that have no statistics.
Use this feature by running the GATHER_SCHEMA_STATS and GATHER_DATABASE_STATS procedures with the options and objlist parameters. Use the following values for the options parameter:
The objlist parameter identifies an output parameter for the LIST STALE and LIST EMPTY options. The objlist parameter is of type DBMS_STATS.OBJECTTAB.
The GATHER STALE option only gathers statistics for tables that have stale statistics and for which you have enabled the MONITORING attribute. To enable monitoring for tables, use the MONITORING keyword of the CREATE TABLE and ALTER TABLE statements as described later in this chapter under the heading "Designating Tables for Monitoring and Automated Statistics Gathering".
The GATHER STALE option maintains up-to-date statistics for the cost-based optimizer. Using this option at regular intervals also avoids the overhead associated with using the ANALYZE statement on all tables at one time. Using the GATHER option can incur significantly greater overhead since this option will likely gather statistics for a greater number of tables than GATHER STALE.
Use a script or job scheduling tool for the GATHER_SCHEMA_STATS and GATHER_DATABASE_STATS procedures to establish a frequency of statistics collection that is appropriate for your application. The frequency of collection intervals should balance the task of providing accurate statistics for the optimizer against the processing overhead incurred by the statistics collection process.
You can use the GATHER_SCHEMA_STATS and GATHER_DATABASE_STATS procedures to create a list of tables with stale statistics. Use this list to identify tables for which you want to manually gather statistics.
You can also use these procedures to create a list of tables with no statistics. Use this list to identify tables for which you want to gather statistics, either automatically or manually.
To automatically gather statistics for a particular table, enable the monitoring attribute using the MONITORING keyword. This keyword is part of the CREATE TABLE and ALTER TABLE statement syntax.
Once enabled, Oracle monitors the table for DML activity. This includes the approximate number of inserts, updates, and deletes for that table since the last time statistics were gathered. Oracle uses this data to identify tables with stale statistics.
View the data Oracle obtains from monitoring these tables by querying the USER_TAB_MODIFICATIONS view.
To disable monitoring of a table, use the NOMONITORING keyword.
|
See Also:
For more information about the CREATE TABLE and ALTER TABLE syntax and the MONITORING and NOMONITORING keywords, please refer to the Oracle8i SQL Reference. |
You can preserve versions of statistics for tables by specifying the stattab, statid, and statown parameters. Use stattab to identify a destination table for archiving previous versions of statistics. Further identify these versions using statid, for example, to denote the date and time the version was made. Use statown to identify a destination schema if it is different from the schema(s) of the actual tables.
The following parameters affect cost-based optimization plans:
You often need to set the following parameters in data warehousing applications:
You rarely need to change the following parameters:
Two parameters address the optimizer's use of indexes for a wide range of statements, particularly nested-loop join statements in both OLTP and DSS applications.
Use the OPTIMIZER_INDEX_COST_ADJ parameter to encourage the use of indexes. This parameter encourages the use of all indexes regardless of their selectivity. It also applies to index use in general rather than to just modeling index caching for nested loop join probes.
Use OPTIMIZER_INDEX_CACHING if these two conditions exists:
In such an environment, this parameter has two advantages over OPTIMIZER_INDEX_COST_ADJ. First, OPTIMIZER_INDEX_CACHING favors using selective indexes. That is, if you use a relatively low value for this parameter, the optimizer effectively models the caches of all non-leaf index blocks. In this case, the optimizer bases the cost of using this index primarily on the basis of its selectivity. Thus, by setting OPTIMIZER_INDEX_CACHING to a low value, you achieve the desired modeling of the index caching without over using possibly undesirable indexes that have poor selectivity.
Second, the effects of using OPTIMIZER_INDEX_CACHING are restricted to modeling the use of cached indexes for nested loop join probes. Thus, its use has fewer side effects.
This section describes additional information for using the cost-based approach.
Cost-based optimization assumes that queries are executed on a multi-user system with fairly low buffer cache hit rates. Thus, a plan selected by the cost-based optimizer may not be the best plan for a single-user system with a large buffer cache. Furthermore, timing a query plan on a single-user system with a large cache may not be a good predictor of performance for the same query on a busy multi-user system.
Analyzing a table uses more system resources than analyzing an index. It may be helpful to analyze the indexes for a table separately, or collect statistics during index creation with a higher sampling rate.
Use of access path and join method hints invokes cost-based optimization. Since cost-based optimization is dependent on statistics, it is important to gather statistics for all tables referenced in a query that has hints, even though rule-based optimization may have been selected as the system default.
User-defined structures such as columns, standalone functions, types, packages, indexes, and indextypes, are generally "opaque" to the optimizer. That is, the optimizer does not have statistics about these structures, nor can it compute accurate selectivities or costs for queries that use them.
For this reason, Oracle strongly encourages you to provide statistics collection, selectivity, and cost functions for user-defined structures. This is because the optimizer defaults can be inaccurate and lead to expensive execution plans.
Oracle supports rule-based optimization, but you should design new applications to use cost-based optimization. You should also use cost-based optimization for data warehousing applications because the cost-based optimizer supports new and enhanced features for DSS.Much of the more recent performance enhancements, such as hash joins, improved star query processing, and histograms, are only available through cost-based optimization.
If you have developed OLTP applications using version 6 of Oracle and have tuned your SQL statements carefully based on the rules of the optimizer, you may want to continue using rule-based optimization when you upgrade these applications to a new version of Oracle.
If you neither collect statistics nor add hints to your SQL statements, your statements will use rule-based optimization. However, you should eventually migrate your existing applications to use the cost-based approach, because eventually, the rule-based approach will not be available in the Oracle server.
If you are using applications provided by third-party vendors, check with the vendors to determine which type of optimization is best suited to that application.
You can enable cost-based optimization on a trial basis simply by collecting statistics. You can then return to rule-based optimization by deleting the statistics or by setting either the value of the OPTIMIZER_MODE initialization parameter or the OPTIMIZER_MODE option of the ALTER SESSION statement to RULE. You can also use this value if you want to collect and examine statistics for your data without using the cost-based approach.
|
See Also:
For procedures to migrate from the rule-based optimizer to the cost-based optimizer, refer to "Plan Stability Procedures for the Cost-based Optimizer". For an explanation of how to gather statistics, please refer to "Gathering Statistics with the DBMS_STATS Package". |
Plan Stability prevents certain database environment changes from affecting the performance characteristics of your applications. Such changes include changes to the optimizer mode settings and changes to parameters affecting the sizes of memory structures such as SORT_AREA_SIZE, and BITMAP_MERGE_AREA_SIZE. Plan Stability is most useful when you cannot risk any performance changes in your applications.
Plan Stability preserves execution plans in "stored outlines". Oracle can create a stored outline for one or all SQL statements. The optimizer then generates equivalent execution plans from the outlines when you enable the use of stored outlines.
The plans Oracle maintains in stored outlines remain consistent despite changes to your system's configuration or statistics. Using stored outlines also stabilizes the generated execution plan if the optimizer changes in subsequent Oracle releases. You can also group outlines into categories and control which category of outlines Oracle uses to simplify outline administration and deployment.
Plan Stability also facilitates migration from the rule-based optimizer to the cost-based optimizer when you upgrade to a new version of Oracle.
|
Note: If you develop applications for mass distribution, you can use stored outlines to ensure all your customers access the same execution plans. For more information about this, please refer to "Automated Statistics Gathering". |
The degree to which Plan Stability controls execution plans is dictated by the extent to which Oracle's hint mechanism controls access paths because Oracle uses hints to record stored plans. Plan Stability also relies on "exact text matching" of queries when determining whether a query has a stored outline.
Similar SQL statements could potentially share stored outlines, however, there is a one-to-one correspondence between SQL text and its stored outline. If you specify a different literal in a predicate, then a different outline applies. To avoid this, replace literals in your applications with bind variables. This gives your SQL statements the exact textual match for outline sharing.
|
See Also:
For more information on how Oracle matches SQL statements to outlines, please refer to the following heading, "Matching SQL Statements with Outlines". |
Plan Stability relies on preserving execution plans at a point in time when performance is satisfactory. In many environments, however, attributes for datatypes such as "dates" or "order numbers" can change rapidly. In these cases, permanent use of an execution plan may result in performance degradation over time as the data characteristics change.
This implies that techniques that rely on preserving plans in dynamic environments are somewhat contrary to the purpose of using cost-based optimization. Cost-based optimization attempts to produce execution plans based on statistics that accurately reflect the state of the data. Thus, you must balance the need to control plan stability with the benefit obtained from the optimizer's ability to adjust to changes in data characteristics.
An outline consists primarily of a set of hints that is equivalent to the optimizer's results for the execution plan generation of a particular SQL statement. When Oracle creates an outline, Plan Stability examines the optimization results using the same data used to generate the execution plan. That is, Oracle uses the input to the execution plan to generate an outline and not the execution plan itself.
Oracle uses one of two scenarios when compiling SQL statements and matching them with outlines. The first scenario is that if you disable outline use by setting the system/session parameter USE_STORED_OUTLINES to FALSE, Oracle does not attempt to match SQL text to outlines. The second scenario involves the following two "matching" steps.
First, if you specify that Oracle must use a particular outline category, only outlines in that category are candidates for matching. Second, if the SQL text of the incoming statement exactly matches the SQL text in an outline in that category, Oracle considers both texts identical and Oracle uses the outline. Oracle considers any differences a mismatch.
Differences include spacing changes, carriage return variations, embedded hints, or even differences in comment text. These rules are identical to the rules for cursor matching.
Oracle stores outline data in the OL$ table and hint data in the OL$HINTS table. Unless you remove them, Oracle retains outlines indefinitely. Oracle retains execution plans in cache and only recreates them if they become invalid or if the cache is not large enough to hold all of them.
The only effect outlines have on caching execution plans is that the outline's category name is used in addition to the SQL text to identify whether the plan is in cache. This ensures Oracle does not use an execution plan compiled under one category to execute a SQL statement that Oracle should compile under a different category.
Settings for several parameters, especially those ending with the suffix "_ENABLED", must be consistent across execution environments for outlines to function properly. These parameters are:
Oracle can automatically create outlines for all SQL statements, or you can create them for specific SQL statements. In either case, the outlines derive their input from the rule-based or cost-based optimizers.
Oracle creates stored outlines automatically when you set the parameter CREATE_STORED_OUTLINES to TRUE. When activated, Oracle creates outlines for all executed SQL statements. You can also create stored outlines for specific statements using the CREATE OUTLINE statement.
|
See Also:
For more information on the CREATE OUTLINE statement, please refer to the Oracle8i SQL Reference. For information on moving from the rule-based optimizer to the cost-based optimizer, refer to "Using Outlines to Move to the Cost-based Optimizer". |
You can create outline category names and assign outlines to them. As mentioned, this simplifies outline management because you can manipulate all outlines within a category at one time.
Both the CREATE_STORED_OUTLINES parameter and the CREATE OUTLINE statement accept category names. For either of these, if you specify a category name, Oracle assigns all subsequently created outlines to that category until you reset the category name or suspend outline generation by setting the CREATE_STORED_OUTLINES parameter to FALSE.
If you set CREATE_STORED_OUTLINES to TRUE or use the CREATE OUTLINE statement without a category name, Oracle assigns outlines to the category name of DEFAULT.
|
See Also:
For more information on the CREATE_- and USE_STORED_OUTLINES parameters, please refer to the Oracle8i Reference. |
To use stored outlines when Oracle compiles a SQL statement, set the system parameter USE_STORED_OUTLINES to TRUE or to a category name. If you set USE_STORED_OUTLINES to TRUE, Oracle uses outlines in the DEFAULT category. If you specify a category with the USE_STORED_OUTLINES parameter, Oracle uses outlines in that category until you re-set the USE_STORED_OUTLINES parameter to another category name or until you suspend outline use by setting USE_STORED_OUTLINES to FALSE. If you specify a category name and Oracle does not find an outline in that category that matches the SQL statement, Oracle searches for an outline in the DEFAULT category.
The designated outlines only control the compilation of SQL statements that have outlines. If you set USE_STORED_OUTLINES to FALSE, Oracle does not use outlines. When you set USE_STORED_OUTLINES to FALSE and you set CREATE_STORED_OUTLINES to TRUE, Oracle creates outlines but does not use them.
When you activate the use of stored outlines, Oracle always uses the cost-based optimizer. This is because outlines rely on hints, and to be effective, most hints require the cost-based optimizer.
You can access information about outlines and related hint data that Oracle stores in the data dictionary from these views:
For example, use this syntax to obtain outline information from the USER_OUTLINES view where the outline category is 'MYCAT':
SELECT NAME,SQL_TEXT FROM USER_OUTLINES WHERE CATEGORY='mycat';
Oracle responds by displaying the names and text of all outlines in category "MYCAT". To see all generated hints for the outline "NAME1", for example, use this syntax:
SELECT HINT FROM USER_OUTLINE_HINTS WHERE NAME='name1';
|
See Also:
If necessary, you can use the procedure to move outline tables from one tablespace to another as described under the heading "Procedure for Moving Outline Tables from One Tablespace to Another". |
Use procedures in the OUTLN_PKG package to manage stored outlines and their outline categories. OUTLN_PKG provides these procedures:
You can remove unneeded outlines using the DROP_UNUSED procedure of OUTLN_PKG. This procedure improves performance if your tablespace becomes saturated with an excessive number of outlines that Oracle will never use.
The syntax for the DROP_UNUSED procedure is:
OUTLN_PKG.DROP_UNUSED;
Execute the DROP_BY_CAT procedure to drop outlines within a specific category.
The syntax and parameter for the DROP_BY_CAT procedure are:
OUTLN_PKG.DROP_BY_CAT( category_name);
|
category_name |
Name of the category you want to drop. |
Reassign outlines from one category to another by executing the UPDATE_BY_CAT procedure.
The syntax and parameters for the UPDATE_BY_CAT procedure are:
OUTLN_PKG.UPDATE_BY_CAT( old_category_name, new_category_name);
|
old_category_name |
Specifies the name of the outline category that you want to reassign to a new category. |
|
new_category_name |
Specifies the name of the category to which you want to assign the outline. |
|
See Also:
For more information about the CREATE, DROP and ALTER statements, please refer to the Oracle8i SQL Reference. |
Oracle creates the USER_OUTLINES and USER_OUTLINE_HINTS views based on data in the OL$ and OL$HINTS tables respectively. Oracle creates these tables in the SYS tablespace using a schema called "OUTLN". If the outlines use too much space in the SYS tablespace, you can move them. To do this, create a separate tablespace and move the outline tables into it using the following procedure.
Use this procedure to move outline tables:
EXP OUTLN/OUTLN FILE = exp_file TABLES = 'OL$' 'OL$HINTS' SILENT=y
CONNECT OUTLN/outln_password; DROP TABLE OL$; CONNECT OUTLN/outln_password; DROP TABLE OL$HINTS;
CREATE TABLESPACE outln_ts DATAFILE 'tspace.dat' SIZE 2MB DEFAULT STORAGE (INITIAL 10KB NEXT 20KB MINEXTENTS 1 MAXEXTENTS 999 PCTINCREASE 10) ONLINE;
IMPORT OUTLN/outln_password FILE=exp_file TABLES = 'OL$' 'OL$HINTS' IGNORE=y SILENT=y
The IMPORT statement re-creates the OL$ and OL$HINTS tables in the schema named OUTLN, but the schema now resides in a new tablespace called "OUTLN_TS".
This section describes procedures you can use to significantly improve performance by taking advantage of cost-based optimizer functionality. Plan Stability provides a way to preserve your system's targeted execution plans for which performance is satisfactory while also taking advantage of new cost-based optimizer features for the rest of your SQL statements.
Topics covered in this section are:
If your application was developed using the rule-based optimizer, a considerable amount of effort may have gone into manually tuning the SQL statements to optimize performance. You can use Plan Stability to leverage the effort that has already gone into performance tuning by preserving the behavior of the application when upgrading from rule-based to cost-based optimization. By creating outlines for an application before switching to cost-based optimization, the plans generated by the rule-based optimizer can be used while statements generated by newly written applications developed after the switch will use normal, cost-based plans. To create and use outlines for an application, use the following procedure.
ALTER SESSION SET CREATE_STORED_OUTLINES = rbocat;
ALTER SESSION SET CREATE_STORED_OUTLINES = FALSE;
ALTER SESSION SET USE_STORED_OUTLINES = rbocat;
Subject to the limitations of Plan Stability, access paths for this application's SQL statements should be unchanged.
When upgrading to a new version of Oracle under cost-based optimization, there is always a possibility that some SQL statements will have their execution plans changed due to changes in the optimizer. While such changes benefit performance in the vast majority of cases, you might have some applications that perform well and where you would consider any changes in their behavior to be an unnecessary risk. For such applications, you can create outlines before the upgrade using the following procedure.
ALTER SESSION SET CREATE_STORED_OUTLINES = ALL_QUERIES;
ALTER SESSION SET CREATE_STORED_OUTLINES = FALSE;
After the upgrade, you can enable the use of stored outlines, or alternatively, you can use the outlines that were stored as a backup if you find that some statements exhibit performance degradation after the upgrade.
With the latter approach, you can selectively use the stored outlines for such problematic statements as follows:
ALTER OUTLINE outline_name CHANGE CATEGORY TO problemcat;
ALTER SESSION SET USE_STORED_OUTLINES = problemcat;
A test system, separate from the production system, can be useful for conducting experiments with optimizer behavior in conjunction with an upgrade. You can migrate statistics from the production system to the test system using import/export. This may alleviate the need to fill the tables in the test system with data.
You can move outlines between the systems by category. For example, once you create outlines in the PROBLEMCAT category, export them by category using the query-based export option. This is a convenient and efficient way to export only selected outlines from one database to another without exporting all outlines in the source database. To do this, issue these statements:
EXP OUTLN/outln_password FILE=<exp-file> TABLES= 'OL$' 'OL$HINTS' QUERY='WHERE CATEGORY="problemcat"'
As an application designer, you may know information about your data that the optimizer does not know. For example, you may know that a certain index is more selective for certain queries. Based on this information, you may be able to choose a more efficient execution plan than the optimizer. In such a case, use hints to force the optimizer to use the optimal execution plan.
Hints allow you to make decisions usually made by the optimizer. You can use hints to specify:
Hints apply only to the optimization of the statement block in which they appear. A statement block is any one of the following statements or parts of statements:
For example, a compound query consisting of two component queries combined by the UNION operator has two statement blocks, one for each component query. For this reason, hints in the first component query apply only to its optimization, not to the optimization of the second component query.
You can send hints for a SQL statement to the optimizer by enclosing them in a comment within the statement.
A statement block can have only one comment containing hints. This comment can only follow the SELECT, UPDATE, or DELETE keyword. The syntax diagrams show the syntax for hints contained in both styles of comments that Oracle supports within a statement block.
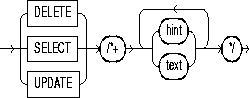
or:
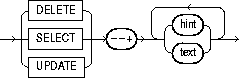
where:
If you specify hints incorrectly, Oracle ignores them but does not return an error:
Other conditions specific to index type appear later in this chapter.
The optimizer recognizes hints only when using the cost-based approach. If you include a hint (except the RULE hint) in a statement block, the optimizer automatically uses the cost-based approach.
The following sections show the syntax of each hint.
The hints described in this section allow you to choose between the cost-based and the rule-based optimization approaches and, with the cost-based approach, either a goal of best throughput or best response time.
If a SQL statement has a hint specifying an optimization approach and goal, the optimizer uses the specified approach regardless of the presence or absence of statistics, the value of the OPTIMIZER_MODE initialization parameter, and the OPTIMIZER_MODE parameter of the ALTER SESSION statement.
The ALL_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best throughput (that is, minimum total resource consumption).
The syntax of this hint is as follows:

For example, the optimizer uses the cost-based approach to optimize this statement for best throughput:
SELECT /*+ ALL_ROWS */ empno, ename, sal, job FROM emp WHERE empno = 7566;
The FIRST_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best response time (minimum resource usage to return first row).
This hint causes the optimizer to make these choices:
The syntax of this hint is as follows:

For example, the optimizer uses the cost-based approach to optimize this statement for best response time:
SELECT /*+ FIRST_ROWS */ empno, ename, sal, job FROM emp WHERE empno = 7566;
The optimizer ignores this hint in DELETE and UPDATE statement blocks and in SELECT statement blocks that contain any of the following syntax:
These statements cannot be optimized for best response time because Oracle must retrieve all rows accessed by the statement before returning the first row. If you specify this hint in any of these statements, the optimizer uses the cost-based approach and optimizes for best throughput.
If you specify either the ALL_ROWS or FIRST_ROWS hint in a SQL statement and the data dictionary does not have statistics about tables accessed by the statement, the optimizer uses default statistical values (such as allocated storage for such tables) to estimate the missing statistics and subsequently to choose an execution plan.
These estimates may not be as accurate as those generated by the ANALYZE statement. Therefore, use the ANALYZE statement to generate statistics for all tables accessed by statements that use cost-based optimization. If you specify hints for access paths or join operations along with either the ALL_ROWS or FIRST_ROWS hint, the optimizer gives precedence to the access paths and join operations specified by the hints.
The CHOOSE hint causes the optimizer to choose between the rule-based and cost-based approaches for a SQL statement. The optimizer bases its selection on the presence of statistics for the tables accessed by the statement. If the data dictionary has statistics for at least one of these tables, the optimizer uses the cost-based approach and optimizes with the goal of best throughput. If the data dictionary does not have statistics for these tables, it uses the rule-based approach.
The syntax of this hint is as follows:

For example:
SELECT /*+ CHOOSE */ empno, ename, sal, job FROM emp WHERE empno = 7566;
The RULE hint explicitly chooses rule-based optimization for a statement block. It also makes the optimizer ignore other hints specified for the statement block.
The syntax of this hint is as follows:

For example, the optimizer uses the rule-based approach for this statement:
SELECT --+ RULE empno, ename, sal, job FROM emp WHERE empno = 7566;
The RULE hint, along with the rule-based approach, may not be supported in future versions of Oracle.
Each hint described in this section suggests an access method for a table.
Specifying one of these hints causes the optimizer to choose the specified access path only if the access path is available based on the existence of an index or cluster and on the syntactic constructs of the SQL statement. If a hint specifies an unavailable access path, the optimizer ignores it.
You must specify the table to be accessed exactly as it appears in the statement. If the statement uses an alias for the table, use the alias rather than the table name in the hint. The table name within the hint should not include the schema name if the schema name is present in the statement.
|
Note: For access path hints, Oracle ignores the hint if you specify the SAMPLE option in the FROM clause of a SELECT statement. For more information on the SAMPLE option, please refer to Oracle8i Concepts and Oracle8i Reference. |
The FULL hint explicitly chooses a full table scan for the specified table.
The syntax of this hint is as follows:
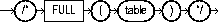
where table specifies the name or alias of the table on which the full table scan is to be performed.
For example, Oracle performs a full table scan on the ACCOUNTS table to execute this statement, even if there is an index on the ACCNO column that is made available by the condition in the WHERE clause:
SELECT /*+ FULL(A) DON'T USE THE INDEX ON ACCNO */ ACCNO, BAL FROM ACCOUNTS A WHERE ACCNO = 7086854;
The ROWID hint explicitly chooses a table scan by rowid for the specified table. The syntax of the ROWID hint is:
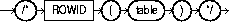
where table specifies the name or alias of the table on which the table access by rowid is to be performed.
The CLUSTER hint explicitly chooses a cluster scan to access the specified table. It applies only to clustered objects. The syntax of the CLUSTER hint is:
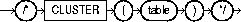
where table specifies the name or alias of the table to be accessed by a cluster scan.
The following example illustrates the use of the CLUSTER hint.
SELECT --+ CLUSTER EMP ENAME, DEPTNO FROM EMP, DEPT WHERE DEPTNO = 10 AND EMP.DEPTNO = DEPT.DEPTNO;
The HASH hint explicitly chooses a hash scan to access the specified table. It applies only to tables stored in a cluster. The syntax of the HASH hint is:
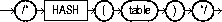
where table specifies the name or alias of the table to be accessed by a hash scan.
The HASH_AJ hint transforms a NOT IN subquery into a hash anti-join to access the specified table. The syntax of the HASH_AJ hint is:

The HASH_SJ hint transforms a correlated EXISTS subquery into a hash semi-join to access the specified table. The syntax of the HASH_SJ hint is:

The INDEX hint explicitly chooses an index scan for the specified table. You can use the INDEX hint for domain, B*-tree, and bitmap indexes. However, Oracle recommends using INDEX_COMBINE rather than INDEX for bitmap indexes because it is a more versatile hint.
The syntax of the INDEX hint is:

where:
|
table |
Specifies the name or alias of the table associated with the index to be scanned. |
|
index |
Specifies an index on which an index scan is to be performed. |
This hint may optionally specify one or more indexes:
For example, consider this query that selects the name, height, and weight of all male patients in a hospital:
SELECT name, height, weight FROM patients WHERE sex = 'm';
Assume there is an index on the SEX column and that this column contains the values M and F. If there are equal numbers of male and female patients in the hospital, the query returns a relatively large percentage of the table's rows and a full table scan is likely to be faster than an index scan. However, if a very small percentage of the hospital's patients are male, the query returns a relatively small percentage of the table's rows and an index scan is likely to be faster than a full table scan.
The number of occurrences of each distinct column value is not available to the optimizer. The cost-based approach assumes that each value has an equal probability of appearing in each row. For a column having only two distinct values, the optimizer assumes each value appears in 50% of the rows, so the cost-based approach is likely to choose a full table scan rather than an index scan.
If you know that the value in the WHERE clause of your query appears in a very small percentage of the rows, you can use the INDEX hint to force the optimizer to choose an index scan. In this statement, the INDEX hint explicitly chooses an index scan on the SEX_INDEX, the index on the SEX column:
SELECT /*+ INDEX(PATIENTS SEX_INDEX) USE SEX_INDEX, SINCE THERE ARE FEW MALE PATIENTS */ NAME, HEIGHT, WEIGHT FROM PATIENTS WHERE SEX = 'M';
The INDEX hint applies to inlist predicates; it forces the optimizer to use the hinted index, if possible, for an inlist predicate. Multi-column inlists will not use an index.
This hint is useful if you are using distributed query optimization. For more information about this, please refer to Oracle8i Distributed Database Systems.
The INDEX_ASC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in ascending order of their indexed values. The syntax of the INDEX_ASC hint is:

Each parameter serves the same purpose as in the INDEX hint.
Because Oracle's default behavior for a range scan is to scan index entries in ascending order of their indexed values, this hint does not specify anything more than the INDEX hint. However, you may want to use the INDEX_ASC hint to specify ascending range scans explicitly, should the default behavior change.
This hint is useful if you are using distributed query optimization.
|
See Also:
For more information about the INDEX_ASC hint, please refer to Oracle8i Distributed Database Systems. |
The INDEX_COMBINE hint explicitly chooses a bitmap access path for the table. If no indexes are given as arguments for the INDEX_COMBINE hint, the optimizer uses whatever Boolean combination of bitmap indexes has the best cost estimate for the table. If certain indexes are given as arguments, the optimizer tries to use some Boolean combination of those particular bitmap indexes. The syntax of INDEX_COMBINE is:

This hint is useful for bitmap indexes and if you are using distributed query optimization. For more information about this, please refer to Oracle8i Distributed Database Systems.
The INDEX_JOIN hint explicitly instructs the optimizer to use an index join as an access path. For the hint to have a positive effect, a sufficiently small number of indexes must exist that contain all the columns required to resolve the query.

where:
|
table |
Specifies the name or alias of the table associated with the index to be scanned. |
|
index |
Specifies an index on which an index scan is to be performed. |
The INDEX_DESC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in descending order of their indexed values. The syntax of the INDEX_DESC hint is:

Each parameter serves the same purpose as in the INDEX hint. This hint has no effect on SQL statements that access more than one table. Such statements always perform range scans in ascending order of the indexed values.
This hint is useful if you are using distributed query optimization. For more information about this, please refer to Oracle8i Distributed Database Systems.
This hint causes a fast full index scan to be performed rather than a full table scan. The syntax of INDEX_FFS is:

This hint is useful if you are using distributed query optimization. For more information about this, please refer to Oracle8i Distributed Database Systems.
The NO_INDEX hint explicitly disallows a set of indexes for the specified table. The syntax of the NO_INDEX hint is:
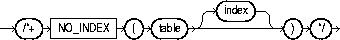
Use this hint to optionally specify one or more indexes:
The NO_INDEX hint applies to function-based, B*-tree, bitmap, cluster, or domain indexes.
If a NO_INDEX hint and an index hint (INDEX, INDEX_ASC, INDEX_DESC, INDEX_COMBINE, or INDEX_FFS) both specify the same indexes, then both the NO_INDEX hint and the index hint are ignored for the specified indexes and the optimizer will consider the specified indexes.
This hint is useful if you are using distributed query optimization. For more information about this, please refer to Oracle8i Distributed Database Systems.
The MERGE_AJ hint transforms a NOT IN subquery into a merge anti-join to access the specified table. The syntax of the MERGE_AJ hint is:
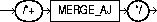
The MERGE_SJ hint transforms a correlated EXISTS subquery into a merge semi-join to access the specified table. The syntax of the MERGE_SJ hint is:
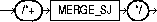
The AND_EQUAL hint explicitly chooses an execution plan that uses an access path that merges the scans on several single-column indexes. The syntax of the AND_EQUAL hint is:
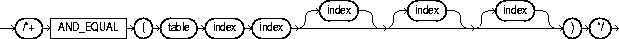
where:
The USE_CONCAT hint forces combined OR conditions in the WHERE clause of a query to be transformed into a compound query using the UNION ALL set operator. Normally, this transformation occurs only if the cost of the query using the concatenations is cheaper than the cost without them.
The USE_CONCAT hint turns off inlist processing and OR-expands all disjunctions, including inlists.
The syntax of this hint is:
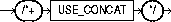
The NO_EXPAND hint prevents the cost-based optimizer from considering OR-expansion for queries having OR conditions or INLISTS in the WHERE clause. Normally, the optimizer would consider using OR expansion and use this method if it decides the cost is lower than not using it.
The syntax of this hint is:

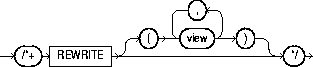
Use the REWRITE hint with or without a view list. If you use REWRITE with a view list and the list contains an eligible materialized view, Oracle uses that view regardless of its cost. Oracle does not consider views outside of the list. If you do not specify a view list, Oracle searches for an eligible materialized view and always uses it regardless of its cost.
The syntax of this hint is:
|
See Also:
For more information on materialized views, please refer to Oracle8i Concepts and to Oracle8i Application Developer's Guide - Fundamentals. |
Use the NOREWRITE hint on any query block of a request. This hint disables query rewrite for the query block, overriding the setting of the parameter QUERY_REWRITE_ENABLED.
The syntax of this hint is:

The hints in this section suggest join orders:
The ORDERED hint causes Oracle to join tables in the order in which they appear in the FROM clause.
The syntax of this hint is:
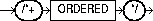
For example, this statement joins table TAB1 to table TAB2 and then joins the result to table TAB3:
SELECT /*+ ORDERED */ TAB1.COL1, TAB2.COL2, TAB3.COL3 FROM TAB1, TAB2, TAB3 WHERE TAB1.COL1 = TAB2.COL1 AND TAB2.COL1 = TAB3.COL1;
If you omit the ORDERED hint from a SQL statement performing a join, the optimizer chooses the order in which to join the tables. You may want to use the ORDERED hint to specify a join order if you know something about the number of rows selected from each table that the optimizer does not. Such information would allow you to choose an inner and outer table better than the optimizer could.
The STAR hint forces a star query plan to be used if possible. A star plan has the largest table in the query last in the join order and joins it with a nested loops join on a concatenated index. The STAR hint applies when there are at least 3 tables, the large table's concatenated index has at least 3 columns, and there are no conflicting access or join method hints. The optimizer also considers different permutations of the small tables.
The syntax of this hint is:

Usually, if you analyze the tables, the optimizer selects an efficient star plan. You can also use hints to improve the plan. The most precise method is to order the tables in the FROM clause in the order of the keys in the index, with the large table last. Then use the following hints:
/*+ ORDERED USE_NL(FACTS) INDEX(FACTS FACT_CONCAT) */
Where "facts" is the table and "fact_concat" is the index. A more general method is to use the STAR hint.
Each hint described in this section suggests a join operation for a table.
You must specify a table to be joined exactly as it appears in the statement. If the statement uses an alias for the table, you must use the alias rather than the table name in the hint. The table name within the hint should not include the schema name, if the schema name is present in the statement.
Use of the USE_NL and USE_MERGE hints is recommended with the ORDERED hint. Oracle uses these hints when the referenced table is forced to be the inner table of a join, and they are ignored if the referenced table is the outer table.
The USE_NL hint causes Oracle to join each specified table to another row source with a nested loops join using the specified table as the inner table. The syntax of the USE_NL hint is:
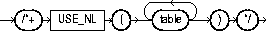
where table is the name or alias of a table to be used as the inner table of a nested loops join.
For example, consider this statement, which joins the ACCOUNTS and CUSTOMERS tables. Assume that these tables are not stored together in a cluster:
SELECT ACCOUNTS.BALANCE, CUSTOMERS.LAST_NAME, CUSTOMERS.FIRST_NAME FROM ACCOUNTS, CUSTOMERS WHERE ACCOUNTS.CUSTNO = CUSTOMERS.CUSTNO;
Since the default goal of the cost-based approach is best throughput, the optimizer will choose either a nested loops operation or a sort-merge operation to join these tables, depending on which is likely to return all the rows selected by the query more quickly.
However, you may want to optimize the statement for best response time, or the minimal elapsed time necessary to return the first row selected by the query, rather than best throughput. If so, you can force the optimizer to choose a nested loops join by using the USE_NL hint. In this statement, the USE_NL hint explicitly chooses a nested loops join with the CUSTOMERS table as the inner table:
SELECT /*+ ORDERED USE_NL(CUSTOMERS) USE N-L TO GET FIRST ROW FASTER */ ACCOUNTS.BALANCE, CUSTOMERS.LAST_NAME, CUSTOMERS.FIRST_NAME FROM ACCOUNTS, CUSTOMERS WHERE ACCOUNTS.CUSTNO = CUSTOMERS.CUSTNO;
In many cases, a nested loops join returns the first row faster than a sort-merge join. A nested loops join can return the first row after reading the first selected row from one table and the first matching row from the other and combining them, while a sort-merge join cannot return the first row until after reading and sorting all selected rows of both tables and then combining the first rows of each sorted row source.
The USE_MERGE hint causes Oracle to join each specified table with another row source with a sort-merge join. The syntax of the USE_MERGE hint is:
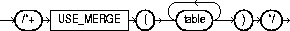
where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a sort-merge join.
The USE_HASH hint causes Oracle to join each specified table with another row source with a hash join. The syntax of the USE_HASH hint is:
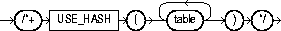
where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a hash join.
The DRIVING_SITE hint forces query execution to be done at a different site than that selected by Oracle. This hint can be used with either rule-based or cost-based optimization. The syntax of this hint is:
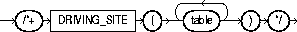
where table is the name or alias for the table at which site the execution should take place.
Example:
SELECT /*+DRIVING_SITE(DEPT)*/ * FROM EMP, DEPT@RSITE WHERE EMP.DEPTNO = DEPT.DEPTNO;
If this query is executed without the hint, rows from DEPT will be sent to the local site and the join will be executed there. With the hint, the rows from EMP will be sent to the remote site and the query will be executed there, returning the result to the local site.
This hint is useful if you are using distributed query optimization. For more information about this, please refer to Oracle8i Distributed Database Systems.
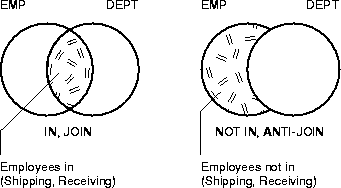
As illustrated in Figure 7-1, the SQL IN predicate can be evaluated using a join to intersect two sets. Thus emp.deptno can be joined to dept.deptno to yield a list of employees in a set of departments.
Alternatively, the SQL NOT IN predicate can be evaluated using an anti-join to subtract two sets. Thus emp.deptno can be anti-joined to dept.deptno to select all employees who are not in a set of departments. Thus you can get a list of all employees who are not in the Shipping or Receiving departments.
For a specific query, place the MERGE_AJ or HASH_AJ hints into the NOT IN subquery. MERGE_AJ uses a sort-merge anti-join and HASH_AJ uses a hash anti-join.
For example:
SELECT * FROM EMP WHERE ENAME LIKE 'J%' AND DEPTNO IS NOT NULL AND DEPTNO NOT IN (SELECT /*+ HASH_AJ */ DEPTNO FROM DEPT WHERE DEPTNO IS NOT NULL AND LOC = 'DALLAS');
If you wish the anti-join transformation always to occur if the conditions in the previous section are met, set the ALWAYS_ANTI_JOIN initialization parameter to MERGE or HASH. The transformation to the corresponding anti-join type then takes place whenever possible.
For a specific query, place the HASH_SJ or MERGE_SJ hint into the EXISTS subquery. HASH_SJ uses a hash semi-join and MERGE_SJ uses a sort merge semi-join. For example:
SELECT * FROM T1 WHERE EXISTS (SELECT /*+ HASH_SJ */ * FROM T WHERE T1.C1 = T2.C1 AND T2.C3 > 5);
This converts the subquery into a special type of join between t1 and t2 that preserves the semantics of the subquery; that is, even if there is more than one matching row in t2 for a row in t1, the row in t1 will be returned only once.
A subquery will be evaluated as a semi-join only with these limitations:
If you wish the semi-join transformation always to occur if the conditions in the previous section are met, set the ALWAYS_SEMI_JOIN initialization parameter to HASH or MERGE. The transformation to the corresponding semi-join type then takes place whenever possible.
The hints described in this section determine how statements are parallelized or not parallelized when using parallel execution.
The PARALLEL hint lets you specify the desired number of concurrent servers that can be used for a parallel operation. The hint applies to the INSERT, UPDATE, and DELETE portions of a statement as well as to the table scan portion. If any parallel restrictions are violated, the hint is ignored. The syntax is:
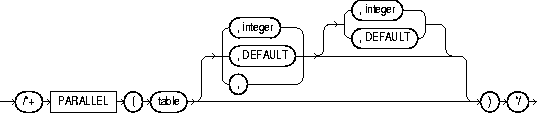
The PARALLEL hint must use the table alias if an alias is specified in the query. The hint can then take two values separated by commas after the table name. The first value specifies the degree of parallelism for the given table, the second value specifies how the table is to be split among the instances of a parallel server. Specifying DEFAULT or no value signifies that the query coordinator should examine the settings of the initialization parameters (described in a later section) to determine the default degree of parallelism.
In the following example, the PARALLEL hint overrides the degree of parallelism specified in the EMP table definition:
SELECT /*+ FULL(SCOTT_EMP) PARALLEL(SCOTT_EMP, 5) */ ENAME FROM SCOTT.EMP SCOTT_EMP;
In the next example, the PARALLEL hint overrides the degree of parallelism specified in the EMP table definition and tells the optimizer to use the default degree of parallelism determined by the initialization parameters. This hint also specifies that the table should be split among all of the available instances, with the default degree of parallelism on each instance.
SELECT /*+ FULL(SCOTT_EMP) PARALLEL(SCOTT_EMP, DEFAULT,DEFAULT) */ ENAME FROM SCOTT.EMP SCOTT_EMP;
You can use the NOPARALLEL hint to override a PARALLEL specification in the table clause. In general, hints take precedence over table clauses. The syntax of this hint is:
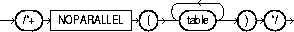
The following example illustrates the NOPARALLEL hint:
SELECT /*+ NOPARALLEL(scott_emp) */ ename FROM scott.emp scott_emp;
The NOPARALLEL hint is equivalent to specifying the hint.
Use the PQ_DISTRIBUTE hint to improve parallel join operation performance. Do this by specifying how rows of joined tables should be distributed among producer and consumer query servers. Using this hint overrides decisions the optimizer would normally make.
Use the EXPLAIN PLAN statement to identify the distribution chosen by the optimizer. The optimizer ignores the distribution hint if both tables are serial. For more information on how Oracle parallelizes join operations, please refer to Oracle8i Concepts.
The syntax of the distribution hint is:
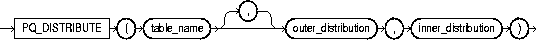
where:
There are six combinations for table distribution:
Only a subset of distribution method combinations for the joined tables is valid as explained in Table 7-3. For example:
Examples: Given two tables R and S that are joined using a hash-join, the following query contains a hint to use hash distribution:
SELECT <column_list> /*+ORDERED PQ_DISTRIBUTE(S HASH HASH) USE_HASH (S)*/ FROM R,S WHERE R.C=S.C;
To broadcast the outer table R, the query should be:
SELECT <column list> /*+ORDERED PQ_DISTRIBUTE(S BROADCAST NONE) USE_HASH (S) */ FROM R,S WHERE R.C=S.C;
When you use the APPEND hint for INSERT, data is simply appended to a table. Existing free space in the block is not used. The syntax of this hint is:

If INSERT is parallelized using the PARALLEL hint or clause, append mode will be used by default. You can use NOAPPEND to override append mode. The APPEND hint applies to both serial and parallel insert.
The append operation is performed in LOGGING or NOLOGGING mode, depending on whether the [NO]LOGGING option is set for the table in question. Use the ALTER TABLE... [NO]LOGGING statement to set the appropriate value.
Certain restrictions apply to the APPEND hint; these are detailed in Oracle8i Concepts. If any of these restrictions are violated, the hint will be ignored.
Use NOAPPEND to override append mode.
Use the PARALLEL_INDEX hint to specify the desired number of concurrent servers that can be used to parallelize index range scans for partitioned indexes. The syntax of the PARALLEL_INDEX hint is:

where:
|
table |
Specifies the name or alias of the table associated with the index to be scanned. |
|
index |
Specifies an index on which an index scan is to be performed (optional). |
The hint can take two values separated by commas after the table name. The first value specifies the degree of parallelism for the given table. The second value specifies how the table is to be split among the instances of a parallel server. Specifying DEFAULT or no value signifies the query coordinator should examine the settings of the initialization parameters (described in a later section) to determine the default degree of parallelism.
For example:
SELECT /*+ PARALLEL_INDEX(TABLE1,INDEX1, 3, 2) +/;
In this example there are 3 parallel execution processes to be used on each of 2 instances.
Use the NOPARALLEL_INDEX hint to override a PARALLEL attribute setting on an index. In this way you can avoid a parallel index scan operation. The syntax of this hint is:

Several additional hints are included in this section:
The CACHE hint specifies that the blocks retrieved for this table are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables. The syntax of this hint is:
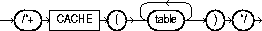
In the following example, the CACHE hint overrides the table's default caching specification:
SELECT /*+ FULL (SCOTT_EMP) CACHE(SCOTT_EMP) */ ENAME FROM SCOTT.EMP SCOTT_EMP;
The NOCACHE hint specifies that the blocks retrieved for this table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. This is the normal behavior of blocks in the buffer cache. The syntax of this hint is:
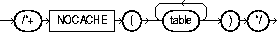
The following example illustrates the NOCACHE hint:
SELECT /*+ FULL(SCOTT_EMP) NOCACHE(SCOTT_EMP) */ ENAME FROM SCOTT.EMP SCOTT_EMP;
Merge a view on a per-query basis by using the MERGE hint. The syntax of this hint is:
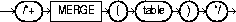
For example:
SELECT /*+ MERGE(V) */ T1.X, V.AVG_Y FROM T1(SELECT X, AVG(Y) AS AVG_Y FROM T2 GROUP BY X) VWHERE T1.X = V.X AND T1.Y = 1;
The NO_MERGE hint causes Oracle not to merge mergeable views. The syntax of the NO_MERGE hint is:
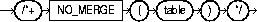
This hint allows the user to have more influence over the way in which the view will be accessed. For example,
SELECT /*+ NO_MERGE(V) */ T1.X, V.AVG_Y FROM T1(SELECT X, AVG(Y) AS AVG_Y FROM T2 GROUP BY X) VWHERE T1.X = V.X AND T1.Y = 1;
causes view v not to be merged.
When the NO_MERGE hint is used without an argument, it should be placed in the view query block. When NO_MERGE is used with the view name as an argument, it should be placed in the surrounding query.
This hint is useful if you are using distributed query optimization. For more information about this, please refer to Oracle8i Distributed Database Systems.
Use the PUSH_JOIN_PRED hint to force pushing of a join predicate into the view.
The syntax of this hint is:
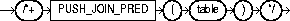
For example:
SELECT /*+ PUSH_JOIN_PRED(V) */ T1.X, V.Y FROM T1(SELECT T2.X, T3.Y FROM T2, T3 SHERE T2.X = T3.X) Vwhere t1.x = v.x and t1.y = 1;
Use the NO_PUSH_JOIN_PRED hint to prevent pushing of a join predicate into the view. The syntax of this hint is:

The PUSH_SUBQ hint causes nonmerged subqueries to be evaluated at the earliest possible place in the execution plan. Normally, subqueries that are not merged are executed as the last step in the execution plan. If the subquery is relatively inexpensive and reduces the number of rows significantly, it will improve performance to evaluate the subquery earlier.
The hint has no effect if the subquery is applied to a remote table or one that is joined using a merge join. The syntax of this hint is:

The STAR_TRANSFORMATION hint makes the optimizer use the best plan in which the transformation has been used. Without the hint, the optimizer could make a cost-based decision to use the best plan generated without the transformation, instead of the best plan for the transformed query.
Even if the hint is given, there is no guarantee that the transformation will take place. The optimizer will only generate the subqueries if it seems reasonable to do so. If no subqueries are generated, there is no transformed query, and the best plan for the untransformed query will be used regardless of the hint.
The syntax of this hint is:

|
See Also:
Oracle8i Concepts for a full discussion of star transformation. Also, the Oracle8i Reference describes STAR_TRANSFORMATION_ENABLED; this parameter causes the optimizer to consider performing a star transformation. |
The ORDERED_PREDICATES hint forces the optimizer to preserve the order of predicate evaluation, except for predicates used as index keys. Use this hint in the WHERE clause of SELECT statements.
If you do not use the ORDERED_PREDICATES hint, Oracle evaluates all predicates in the order specified by the following rules. Predicates:
The syntax of this hint is:
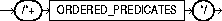
Oracle does not encourage you to use hints inside or on views (or subqueries). This is because you can define views in one context and use them in another. However, such hints can result in unexpected plans. In particular, hints inside views or on views are handled differently depending on whether the view is mergeable into the top-level query.
Should you decide, nonetheless, to use hints with views, the following sections describe the behavior in each case.
This section describes hint behavior with mergeable views.
Optimization approach and goal hints can occur in a top-level query or inside views.
Access method and join hints on referenced views are ignored unless the view contains a single table (or references another view with a single table). For such single-table views, an access method hint or a join hint on the view applies to the table inside the view.
Access method and join hints can appear in a view definition.
PARALLEL, NOPARALLEL, PARALLEL_INDEX and NOPARALLEL_INDEX hints on views are always recursively applied to all the tables in the referenced view. Parallel execution hints in a top-level query override such hints inside a referenced view.
With non-mergeable views, optimization approach and goal hints inside the view are ignored: the top-level query decides the optimization mode.
Since non-mergeable views are optimized separately from the top-level query, access method and join hints inside the view are always preserved. For the same reason, access method hints on the view in the top-level query are ignored.
However, join hints on the view in the top-level query are preserved since, in this case, a non-mergeable view is similar to a table.