Release 8.1.5
A67439-01
Library |
Product |
Contents |
Index |
| Oracle8i Parallel Server Setup and Configuration Guide Release 8.1.5 A67439-01 |
|
![]()
![]()
This chapter provides a conceptual and component overview of Oracle Parallel Server. This information helps you prepare and plan your Oracle Parallel Server installation and configuration in an Oracle8i environment.
Specific topics discussed are:
Oracle Parallel Server is an architecture that allows multiple instances to access a shared database. Oracle Parallel Server offers the following (terms will be described later in this chapter):
An Oracle Parallel Server can handle node or disk failure in a clustered environment with no or minimal downtime. The Oracle Parallel Server architecture provides the following features:
Coordination of each node accessing the shared database provides the following:
This guide describes the features of the Oracle Parallel Server in relation to the Optimal Flexible Architecture (OFA), whereby Oracle software and database directories and file names following a particular format. This guide recommends using tools that adhere to the OFA structure, such as the Oracle Database Configuration Assistant, to configure and administer an Oracle Parallel Server databases. Therefore, all examples and features are described from a OFA point-of-view. You are free to use other naming conventions.
The following components comprise Oracle Parallel Server:
| Component | Description |
|---|---|
|
Oracle8i Enterprise Edition |
Provides the applications and files to manage a database. All other Oracle Parallel Server components are layered on top of Oracle8i Enterprise Edition. |
|
Oracle Parallel Server Option |
Provides the necessary Oracle Parallel Server scripts, initialization files, and data files. |
|
Oracle Parallel Server Management |
Provides a single point for starting, stopping, and monitoring the activity of parallel servers and parallel server instances from within Oracle Enterprise Manager Console. See Chapter 5, "Installing and Configuring Oracle Parallel Server Management" and Chapter 6, "Administering Oracle Parallel Server". |
|
Operating System Dependent layer |
Consists of several software components developed by vendors. The Operating System Dependent layer maps the key OS/cluster-ware services required for proper operation of Oracle Parallel Server. |
A vendor-supplied Operating System Dependent layer that passed certification must be installed after Oracle Parallel Server Option is installed. The Operating System Dependent layer consists of several software components developed by vendors. The Operating System Dependent layer maps the key OS/cluster-ware services required for proper operation of Oracle Parallel Server.
The Operating System Dependent layer consists of:
These components provide key services required for proper operation of the Oracle Parallel Server Option and are used by various clients, such as Integrated Distributed Lock Manager.
Figure 1-1 illustrates the Operating System Dependent components in a cluster with two nodes:
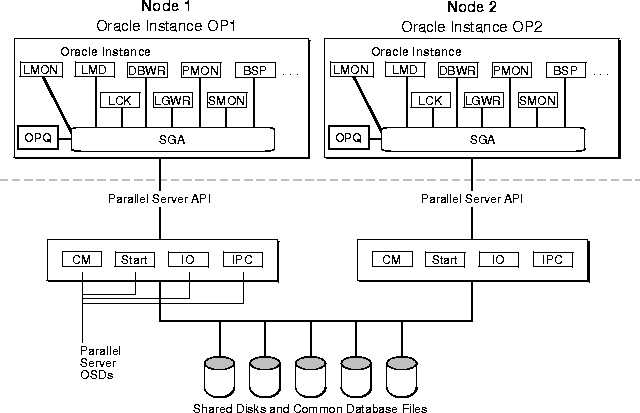
The Cluster Manager (CM) monitors process health, specifically of the database instance. LMON, a background process that monitors the health of the Integrated Distributed Lock Manager, registers and de-registers from CM.
It is critical that all Oracle Parallel Server instances receive the same membership information when events occur. Notification changes cause relevant Oracle Parallel Server recovery operations to be initiated. If any node or instance is determined to be dead or otherwise not a properly functioning part of the system, CM terminates all processes on that node or instance. Thus, any process or thread running Oracle code can safely assume its node or instance is an active member of the system.
If there is a failure, recovery is transparent to user applications. CM automatically reconfigures the system to isolate the failed node and instance and notify Integrated Distributed Lock Manager of the status. Integrated Distributed Lock Manager subsequently recovers any of the locks from the failed node or instance. Oracle Parallel Server can then recover the database to a valid state.
The Integrated Distributed Lock Manager relies on the Cluster Manager for timely and correct information. If the Integrated Distributed Lock Manager cannot get the information it needs, it will shut down the instance.
CM performs the following two types of operations:
The description of these operations is based on Oracle's implementation of the Operating System Dependent layer. Your vendor's implementation may differ.
CM manages access to shared disks and monitors the status of various cluster resources, including nodes, networks and instances.
Node monitoring:
CM determines what groups are up and manages instance members. Each instance registers with its database specific group. This CM function was performed by the Group Membership Service (GMS) prior to this release.
Oracle Parallel Server derives most of its functional benefits from its ability to run on multiple interconnected machines. Oracle Parallel Server relies heavily on the underlying Inter-Process Communication (IPC) component to facilitate this.
IPC defines the protocols and interfaces required for the Oracle Parallel Server environment to transfer reliable messages between instances. Messages are the fundamental logical units of communication in this interface. The core IPC functionality is built around an asynchronous, queued messaging model. IPC is designed to send/receive discrete messages as fast as the hardware allows. With an optimized communication layer, various services can be implemented above it. This is how the Integrated Distributed Lock Manager carries out all of its communication.
The Input/Output (IO) component provides interprocess capabilities that a cluster implementation must support to enable proper operation of the Oracle Parallel Server environment.
The Oracle Parallel Server environment is extremely dependent on the ability of the underlying OS/cluster implementation to support simultaneous disk sharing across all nodes that run coordinated Oracle Parallel Server instances. Unlike switch-over based technologies, all Oracle Parallel Server instances are active and can operate on any database entity in the shared physical database simultaneously. It is this capability that gives Oracle Parallel Server a large portion of its parallel scalability. It is the role of the Integrated Distributed Lock Manager to coordinate the simultaneous access to shared databases in a way that maintains consistency and data integrity.
At a high level, the Oracle Parallel Server shared I/O model can be described as a distributed disk cache implemented across all nodes that define the Oracle Parallel Server cluster. The core of Oracle Parallel Server can be viewed as a major client of the cache. Disk blocks from the shared devices are read into a particular node instance cache only after mediation by the Integrated Distributed Lock Manager. The other node instance may read the same blocks into its cache and operate on them simultaneously. Updates to those blocks are carefully coordinated. In general, all shared disk based I/O operations are mediated by the Integrated Distributed Lock Manager. The set of distributed Integrated Distributed Lock Managers on each node can be thought of as managing the distributed aspects of the cache.
Disk update operations must be carefully coordinated so that all nodes see the same data in a consistent way. Any Oracle Parallel Server instance intending to update a cached data block must enter into a dialog with the Integrated Distributed Lock Manager to ensure it has exclusive right to update the block. Once it does this, the instance is free to update the block until its rights have been revoked by the Integrated Distributed Lock Manager. When the exclusive update right is revoked, the instance with block updates must write the block to disk so that the other node can see the changes. Given this rather high-level view of the Integrated Distributed Lock Manager I/O consistency model, it is clear that disk blocks can migrate around to each instance's block cache and all updates are flushed to disk when an instance other than the owner desires access to the block. It is this property that directly determines the reliance of Oracle Parallel Server on shared disk implementations.
The Startup (START) component initiates the Oracle Parallel Server components in a specific order during instance startup. It is up to the vendor to determine this startup sequence.
Each Oracle Parallel Server instance, a running instance of Oracle8i software, is comprised of a System Global Area (SGA) and Oracle background processes. The SGA is a shared memory region that contains data and control information for an instance. Users can connect to any instance to access the information that resides within the shared database.
Oracle Parallel Server instances coordinate with the following components:
All instances share:
An instance contains:
See Oracle8i Concepts for information about Oracle8i database processes and memory structures.
.The data files are located on disk drives that are shared between the multiple nodes. If one node fails, client applications (written to do so) can re-route users to another node. One of the surviving nodes automatically performs recovery by rolling back any incomplete transactions that the other node was attempting. This ensures the logical consistency of the database.
Following the OFA naming convention, each node's instance has its own INITSID.ORA file that uniquely defines the instance with instance-related parameters. This file calls INITDB_NAME.ORA, which lists common parameters shared from node-to-node. Both files are created by the Oracle Database Configuration Assistant after installation.
The INITSID.ORA file is impacted by a number of elements, including:
If the DB_NAME is OP and the thread IDs are 1, 2, and 3, then the SID for each node is:
| Thread ID | SID |
|---|---|
|
1 |
OP1 |
|
2 |
OP2 |
|
3 |
OP3 |
If the DB_NAME is OP and the node numbers are 0, 1, 4, and 6, then the instance elements are effected in the following manner:
A database is logically divided into tablespaces that contain all data stored in the database. Tablespaces, in turn, are made up of one or more data files.
With Oracle Parallel Server, all participating instances access the same data files.
Figure 1-2 shows the relationship between two Oracle instances and the shared disks on which the data files are stored:
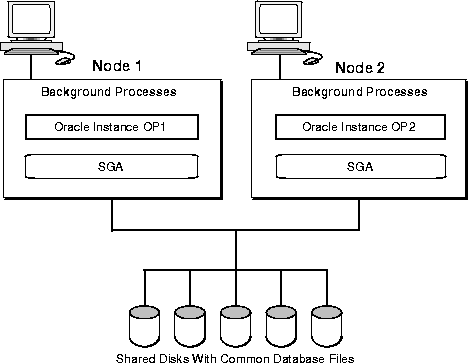
Some of Oracle Parallel Server features to take note of include:
See Oracle8i Parallel Server Concepts and Administration for further information about these and other features.
The Integrated Distributed Lock Manager (IDLM) maintains a list of system resources and provides locking mechanisms to control allocation and modification of Oracle resources. Resources are structures of data. The IDLM does not control access to tables or anything in the database itself. Every process interested in the database resource protected by the IDLM must open a lock on the resource.
Oracle Parallel Server uses the IDLM facility to coordinate concurrent access to resources, such as data blocks and rollback segments, across multiple instances. The Integrated Distributed Lock Manager facility has replaced the external Distributed Lock Manager which was used in earlier releases of Oracle Server.
The IDLM uses the LMON and LMDN processes. LMON manages instance and processes deaths and associated recovery for the IDLM. In particular, LMON handles the part of recovery associated with global locks. The LMDN process handles remote lock requests (those which originate from another instance).
The IDLM:
The IDLM is a resource manager and, thus, does not control access to the database.
A node in a cluster needs to modify block number n in the database file. At the same time, another node needs to update the same block n to complete a transaction.
Without the IDLM, both nodes update the same block at the same time. With the IDLM, only one node is allowed to update the block. The other node must wait. The IDLM ensures that only one instance has the right to update a block at any one time. This provides data integrity by ensuring that all changes made are saved in a consistent manner.
The IDLM uses CM to determine which instances are active. When the instance is started, the LMON and LMDN processes are started and the IDLM registers with CM. The IDLM deregisters with CM when the database is shutdown.
Parallel Cache Management (PCM) provides instance locks (with minimal use of the IDLM) that cover one or more data blocks of any class: data block, index blocks, undo blocks, segment headers, and so on. Oracle Parallel Server uses these instance locks to coordinate access to shared resources. The IDLM maintains the status of the instance locks.
PCM locks ensure cache coherency by forcing instances to acquire a lock before modifying or reading any database block. PCM locks allow only one instance at a time to modify a block. If a block is modified by an instance, the block must first be written to disk before another instance can acquire the PCM lock, read the block, and modify it.
If node 1 needs access to data that is currently in node 2's buffer cache, node 1 can submit a request to the IDLM. Node 2 then writes the needed blocks to disk. Only then is Node 1 notified by the IDLM to read updated and consistent data from the disk.
You use the initialization parameter GC_FILES_TO_LOCKS to specify the number of PCM locks which cover the data blocks in a data file or set of data files. The smallest granularity is one PCM lock per data block; this is the default. PCM locks usually account for the greatest proportion of instance locks in a parallel server.
PCM locks are implemented in two ways:
See the Oracle8i Parallel Server Concepts and Administration for further information about PCM locks.
It is possible to have both fine-grain and hashed locking enabled at the same time.
Below is a comparison of both PCM locks:
| Hash PCM Locks | Fine-Grain PCM Locks |
|---|---|
|
|
Use the table below to choose a PCM lock:
| When to use hashed locks... | When to use fine-grain locks... |
|---|---|
|
|
With Oracle Parallel Query, Oracle can divide the work of processing certain types of SQL statements among multiple query server processes.
When parallel execution is not being used, a single server thread performs all necessary processing for the sequential execution of a SQL statement. For example, to perform a full table scan (such as SELECT * FROM EMP), one thread performs the entire operation.
Oracle Parallel Query performs the operations in parallel using multiple parallel processes. One process, known as the parallel coordinator, dispatches the execution of a statement to several parallel server processes and coordinates the results from all the server processes to send the results back to the user.
The parallel coordinator breaks down execution functions into parallel pieces and then integrates the partial results produced by the parallel server processes. The number of parallel server processes assigned to a single operation is the degree of parallelism for an operation. Multiple operations within the same SQL statement all have the same degree of parallelism
Oracle Parallel Server provides the framework for the Parallel Query Option to work between nodes. The Oracle Parallel Query behaves the same way in Oracle with or without the Parallel Server Option. The only difference is that Oracle Parallel Server enables Oracle Parallel Query to ship queries between nodes so that multiple nodes can execute on behalf of a single query. Here, the server breaks the query up it into smaller operations that run against a common database which resides on shared disks. Because it is performed by the server, this parallelism can occur at a low level of server operation, rather than at an external SQL level.
In some applications, an individual query often consumes a great deal of CPU resource and disk I/O (unlike most online insert or update transactions). To take advantage of multi-processing systems, the data server must parallelize individual queries into units of work which can be processed simultaneously.
If the query were not processed in parallel, disks would be read serially with a single I/O. A single CPU would have to scan all rows in a table. With the query parallelized, disks are read in parallel, with multiple I/Os.
Several CPUs can each scan a part of the table in parallel, and aggregate the results. Parallel query benefits not only from multiple CPUs but also from greater I/O bandwidth availability.
Oracle Parallel Query can run with or without the Oracle Parallel Server. Without the Oracle Parallel Server option, Oracle Parallel Query cannot perform multi-node parallelism. Oracle Parallel Server optimizes Oracle8i Enterprise Edition running on clustered hardware, using a parallel cache architecture to avoid shared memory bottlenecks in OLTP and decision support applications.
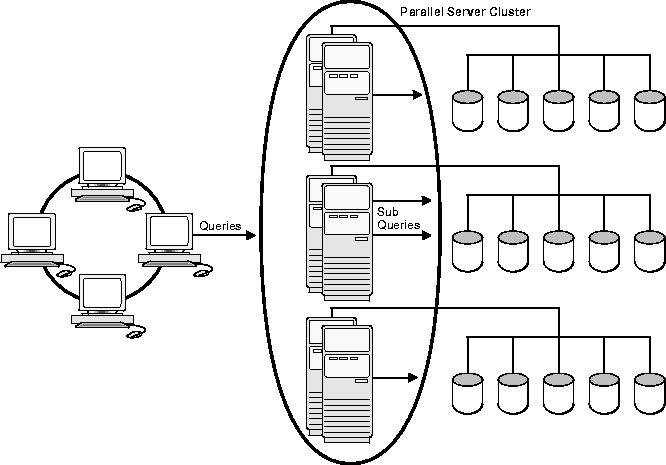
Oracle Parallel Query within Oracle Parallel Server performs parallelism within a node and among nodes via the parallel query slave processes on each node.
A sample SQL statement is shown below:
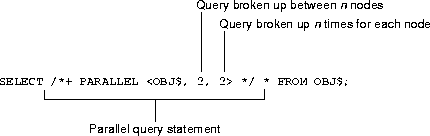
After you have run a query, you can use the information derived from V$PQ_SYSSTAT to view the number of slave processes used, and other information for the system.
See the Oracle8i Concepts for further information about parallel execution.