Release 8.1.5
A67781-01
Library |
Product |
Contents |
Index |
| Oracle8i Concepts Release 8.1.5 A67781-01 |
|
![]()
![]()
These unhappy times call for the building of plans...
Franklin Delano Roosevelt
This chapter introduces the structures that are used during database recovery and describes the Recovery Manager utility, which simplifies backup and recovery operations. The topics in this chapter include:
The procedures necessary to create and maintain the backup and recovery structures are discussed in the Oracle8i Backup and Recovery Guide.
Additional Information:
A major responsibility of the database administrator is to prepare for the possibility of hardware, software, network, process, or system failure. If such a failure affects the operation of a database system, you must usually recover the database and return to normal operation as quickly as possible. Recovery should protect the database and associated users from unnecessary problems and avoid or reduce the possibility of having to duplicate work manually.
Recovery processes vary depending on the type of failure that occurred, the structures affected, and the type of recovery that you perform. If no files are lost or damaged, recovery may amount to no more than restarting an instance. If data has been lost, recovery requires additional steps.
|
Note: The Recovery Manager is a utility that simplifies backup and recovery operations. See "Recovery Manager". |
|
Additional Information:
See the Oracle8i Backup and Recovery Guide for detailed information on Recovery Manager and a description of how to recover from loss of data. |
Several problems can halt the normal operation of an Oracle database or affect database I/O to disk. The following sections describe the most common types. For some of these problems, recovery is automatic and requires little or no action on the part of the database user or database administrator.
A database administrator can do little to prevent user errors (for example, accidentally dropping a table). Usually, user error can be reduced by increased training on database and application principles. Furthermore, by planning an effective recovery scheme ahead of time, the administrator can ease the work necessary to recover from many types of user errors.
Statement failure occurs when there is a logical failure in the handling of a statement in an Oracle program. For example, assume all extents of a table (in other words, the number of extents specified in the MAXEXTENTS parameter of the CREATE TABLE statement) are allocated, and are completely filled with data; the table is absolutely full. A valid INSERT statement cannot insert a row because there is no space available. Therefore, if issued, the statement fails.
If a statement failure occurs, the Oracle software or operating system returns an error code or message. A statement failure usually requires no action or recovery steps; Oracle automatically corrects for statement failure by rolling back the effects (if any) of the statement and returning control to the application. The user can simply re-execute the statement after correcting the problem indicated by the error message.
A process failure is a failure in a user, server, or background process of a database instance (for example, an abnormal disconnect or process termination). When a process failure occurs, the failed subordinate process cannot continue work, although the other processes of the database instance can continue.
The Oracle background process PMON detects aborted Oracle processes. If the aborted process is a user or server process, PMON resolves the failure by rolling back the current transaction of the aborted process and releasing any resources that this process was using. Recovery of the failed user or server process is automatic. If the aborted process is a background process, the instance usually cannot continue to function correctly. Therefore, you must shut down and restart the instance.
When your system uses networks (for example, local area networks, phone lines, and so on) to connect client workstations to database servers, or to connect several database servers to form a distributed database system, network failures (such as aborted phone connections or network communication software failures) can interrupt the normal operation of a database system. For example:
Database instance failure occurs when a problem arises that prevents an Oracle database instance (SGA and background processes) from continuing to work. An instance failure can result from a hardware problem, such as a power outage, or a software problem, such as an operating system crash. Instance failure also results when you issue a SHUTDOWN ABORT or STARTUP FORCE command.
Crash or instance recovery recovers a database to its transaction-consistent state just before instance failure. Crash recovery recovers a database in a single-instance configuration and instance recovery recovers a database in an Oracle Parallel Server configuration.
Recovery from instance failure is automatic. For example, when using the Oracle Parallel Server, another instance performs instance recovery for the failed instance. In single-instance configurations, Oracle performs crash recovery for a database when the database is restarted (mounted and opened to a new instance). The transition from a mounted state to an open state automatically triggers crash recovery, if necessary.
Crash or instance recovery consists of the following steps:
See the Oracle8i Parallel Server Setup and Configuration Guide for a discussion of instance recovery.
See Oracle8i Tuning for a discussion of instance recovery tuning.
Additional Information:
An error can arise when trying to write or read a file that is required to operate an Oracle database. This occurrence is called media failure because there is a physical problem reading or writing to files on the storage medium.
A common example of media failure is a disk head crash, which causes the loss of all files on a disk drive. All files associated with a database are vulnerable to a disk crash, including datafiles, online redo log files, and control files.
The appropriate recovery from a media failure depends on the files affected.
|
Additional Information:
See the Oracle8i Backup and Recovery Guide for a discussion of recovery methods. |
Media failures can affect one or all types of files necessary for the operation of an Oracle database, including datafiles, online redo log files, and control files.
Database operation after a media failure of online redo log files or control files depends on whether the online redo log or control file is multiplexed, as recommended. A multiplexed online redo log or control file simply means that a second copy of the file is maintained. If a media failure damages a single disk, and you have a multiplexed online redo log, the database can usually continue to operate without significant interruption. Damage to a non-multiplexed online redo log causes database operation to halt and may cause permanent loss of data. Damage to any control file, whether it is multiplexed or non-multiplexed, halts database operation once Oracle attempts to read or write the damaged control file (which happens frequently, for example at every checkpoint and log switch).
Media failures that affect datafiles can be divided into two categories: read errors and write errors. In a read error, Oracle discovers it cannot read a datafile and an operating system error is returned to the application, along with an Oracle error indicating that the file cannot be found, cannot be opened, or cannot be read. Oracle continues to run, but the error is returned each time an unsuccessful read occurs. At the next checkpoint, a write error will occur when Oracle attempts to write the file header as part of the standard checkpoint process.
If Oracle discovers that it cannot write to a datafile and Oracle is archiving the filled online redo log files, Oracle returns an error in the DBWn trace file and takes the datafile offline automatically. Only the datafile that cannot be written to is taken offline; the tablespace containing that file remains online.
If the datafile that cannot be written to is in the SYSTEM tablespace, the file is not taken offline. Instead, an error is returned and Oracle shuts down the instance. The reason for this exception is that all files in the SYSTEM tablespace must be online in order for Oracle to operate properly. For the same reason, the datafiles of a tablespace containing active rollback segments must remain online.
If Oracle discovers that it cannot write to a datafile, and Oracle is not archiving the filled online redo log files, the DBWn background process fails and the current instance fails. If the problem is temporary (for example, the disk controller was powered off), crash or instance recovery usually can be performed using the online redo log files, in which case the instance can be restarted. However, if a datafile is permanently damaged and archiving is not used, the entire database must be restored using the most recent cold backup.
Recovery is not needed on read-only datafiles during crash or instance recovery. Recovery during startup verifies that each online read-only file does not need any media recovery. That is, the file was not restored from a backup taken before it was made read-only. If you restore a read-only tablespace from a backup taken before the tablespace was made read-only, you cannot access the tablespace until you complete media recovery.
Several structures of an Oracle database safeguard data against possible failures. This section introduces each of these structures and its role in database recovery.
A database backup consists of backups of the physical files (all datafiles and a control file) that constitute an Oracle database. To begin media recovery after a media failure, Oracle uses file backups to restore damaged datafiles or control files. Replacing a current, possibly damaged, copy of a datafile, tablespace, or database with a backup copy is called restoring that portion of the database.
Oracle offers several options in performing database backups, including:
The redo log, present for every Oracle database, records all changes made in an Oracle database. The redo log of a database consists of at least two redo log files that are separate from the datafiles (which actually store a database's data). As part of database recovery from an instance or media failure, Oracle applies the appropriate changes in the database's redo log to the datafiles, which updates database data to the instant that the failure occurred.
A database's redo log can consist of two parts: the online redo log and the archived redo log.
Every Oracle database has an associated online redo log. The Oracle background process LGWR uses the online redo log to immediately record all changes made through the associated instance. The online redo log consists of two or more pre-allocated files that are reused in a circular fashion to record ongoing database changes.
Optionally, you can configure an Oracle database to archive files of the online redo log once they fill. The online redo log files that are archived are uniquely identified and make up the archived redo log. By archiving filled online redo log files, older redo log information is preserved for operations such as media recovery, while the pre-allocated online redo log files continue to be reused to store the most current database changes.
Datafiles that were restored from backup, or were not closed by a clean database shutdown, may not be completely up to date. These datafiles must be updated by applying the changes in the archived and/or online redo logs. This process is called recovery.
See "Database Archiving Modes" for more information.
Rollback segments are used for a number of functions in the operation of an Oracle database. In general, the rollback segments of a database store the old values of data changed by ongoing transactions (that is, uncommitted transactions).
Among other things, the information in a rollback segment is used during database recovery to "undo" any "uncommitted" changes applied from the redo log to the datafiles. Therefore, if database recovery is necessary, the data is in a consistent state after the rollback segments are used to remove all uncommitted data from the datafiles.
In general, the control file(s) of a database store the status of the physical structure of the database. Certain status information in the control file (for example, the current online redo log file, the names of the datafiles, and so on) guides Oracle during instance or media recovery.
See "Control Files" for more information.
Database buffers in the buffer cache in the SGA are written to disk only when necessary, using a least-recently-used algorithm. Because of the way that the DBWn process uses this algorithm to write database buffers to datafiles, datafiles might contain some data blocks modified by uncommitted transactions and some data blocks missing changes from committed transactions.
Two potential problems can result if an instance failure occurs:
To solve this dilemma, two separate steps are generally used by Oracle for a successful recovery of a system failure: rolling forward with the redo log (cache recovery) and rolling back with the rollback segments (transaction recovery).
The redo log is a set of operating system files that record all changes made to any database buffer, including data, index, and rollback segments, whether the changes are committed or uncommitted. Each redo entry is a group of change vectors describing a single atomic change to the database. The redo log protects changes made to database buffers in memory that have not been written to the datafiles.
The first step of recovery from an instance or disk failure is to roll forward, or reapply all of the changes recorded in the redo log to the datafiles. Because rollback data is also recorded in the redo log, rolling forward also regenerates the corresponding rollback segments. This is called cache recovery.
Rolling forward proceeds through as many redo log files as necessary to bring the database forward in time. Rolling forward usually includes online redo log files and may include archived redo log files.
After roll forward, the data blocks contain all committed changes. They may also contain uncommitted changes that were either saved to the datafiles before the failure, or were recorded in the redo log and introduced during roll forward.
Rollback segments record database actions that should be undone during certain database operations. In database recovery, rollback segments undo the effects of uncommitted transactions previously applied by the rolling forward phase.
After the roll forward, any changes that were not committed must be undone. After redo log files have reapplied all changes made to the database, then the corresponding rollback segments are used. Rollback segments are used to identify and undo transactions that were never committed, yet were either saved to the datafiles before the failure, or were applied to the database during the roll forward. This process is called rolling back or transaction recovery.
Figure 32-1 illustrates rolling forward and rolling back, the two steps necessary to recover from any type of system failure.
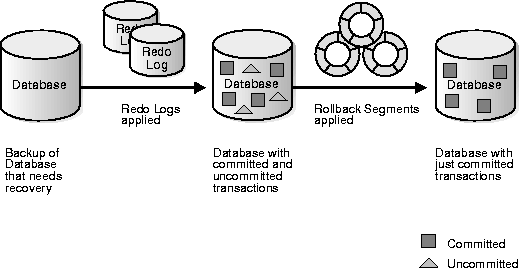
Oracle can roll back multiple transactions simultaneously as needed. All transactions system-wide that were active at the time of failure are marked as DEAD. Instead of waiting for SMON to roll back dead transactions, new transactions can recover blocking transactions themselves to get the row locks they need.
When a database failure occurs, rapid recovery is very important in most situations. Oracle provides a number of methods to make recovery as quick as possible, including:
Recovery reapplies the changes generated by several concurrent processes, and therefore instance or media recovery can take longer than the time it took to initially generate the changes to a database. With serial recovery, a single process applies the changes in the redo log files sequentially. Using parallel recovery, several processes simultaneously apply changes from redo log files.
|
Attention: Oracle8i provides limited parallelism with Recovery Manager; the Oracle8i Enterprise Edition allows unlimited parallelism. See Getting to Know Oracle8i for more information about the features available in Oracle8i and Oracle8i Enterprise Edition. |
Parallel recovery can be performed using three methods:
In general, parallel recovery is most effective at reducing recovery time when several datafiles on several different disks are being recovered concurrently. Crash recovery (recovery after instance failure) and media recovery of many datafiles on many different disk drives are good candidates for parallel recovery.
The performance improvement from parallel recovery is also dependent upon whether the operating system supports asynchronous I/O. If asynchronous I/O is not supported, parallel recovery can dramatically reduce recovery time. If asynchronous I/O is supported, the recovery time may only be slightly reduced by using parallel recovery.
In a typical parallel recovery situation, one process is responsible for reading and dispatching redo entries from the redo log files. This is the dedicated server process that begins the recovery session. The server process reading the redo log files enlists two or more recovery processes to apply the changes from the redo entries to the datafiles.
Figure 32-2 illustrates a typical parallel recovery session.
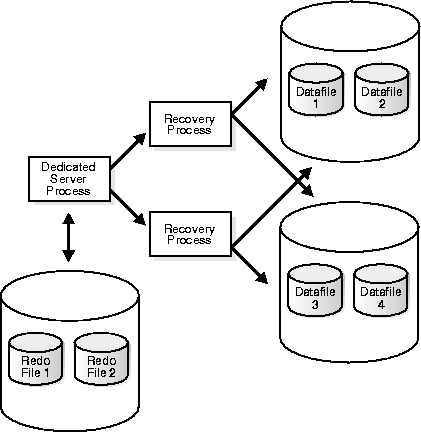
In most situations, one recovery session and one or two recovery processes per disk drive containing datafiles needing recovery is sufficient. Recovery is a disk-intensive activity as opposed to a CPU-intensive activity, and therefore the number of recovery processes needed is dependent entirely upon how many disk drives are involved in recovery. In general, a minimum of eight recovery processes is needed before parallel recovery can show improvement over a serial recovery.
Fast-Start Recovery is an architecture that reduces the time required for rolling forward and makes the recovery bounded and predictable. It also eliminates rollback time from recovery for transactions aborted due to system faults. Fast-Start Recovery includes:
Fast-Start Checkpointing records the position in the redo thread (log) from which crash or instance recovery would need to begin. This position is determined by the oldest dirty buffer in the buffer cache. Each DBWn process continually writes buffers to disk to advance the checkpoint position, with minimal or no overhead during normal processing. Fast-Start Checkpointing improves the performance of crash and instance recovery, but not media recovery.
You can influence recovery performance for situations where there are stringent limitations on the duration of crash or instance recovery. The time required for crash or instance recovery is roughly proportional to the number of data blocks that need to be read or written during the roll forward phase. You can specify a limit, or bound, on the number of data blocks that will need to be processed during roll forward. The Oracle server automatically adjusts the checkpoint write rate to meet the specified roll-forward bound while issuing the minimum number of writes.
You can set the dynamic initialization parameter FAST_START_IO_TARGET to limit the number of blocks that need to be read for crash or instance recovery. Smaller values of this parameter impose higher overhead during normal processing because more buffers have to be written. On the other hand, the smaller the value of this parameter, the better the recovery performance, since fewer blocks need to be recovered. The dynamic initialization parameters LOG_CHECKPOINT_INTERVAL and LOG_CHECKPOINT_TIMEOUT also influence Fast-Start Checkpointing.
|
Additional Information:
See Oracle8i Tuning for information about how to set the value of FAST_START_IO_TARGET, and see Oracle8i Backup and Recovery Guide for a detailed description of checkpoints. |
When a dead transaction holds a row lock on a row that another transaction needs, Fast-Start On-Demand Rollback immediately recovers only the data block under consideration, leaving the rest of the dead transaction to be recovered in the background. This improves the availability of the database for users accessing data that is locked by large dead transactions. If Fast-Start Rollback is not enabled, the user would have to wait until the entire dead transaction was recovered before obtaining the row lock.
Fast-Start Parallel Rollback allows a set of transactions to be recovered in parallel using a group of server processes. This technique is used when SMON determines that the amount of work it takes to perform recovery in parallel is less than the time it takes to recovery serially.
Rapid recovery minimizes the time data is unavailable to users, but it does not address the disruption caused when user sessions fail. Users need to re-establish connections to the database, and work in progress may be lost. Oracle8i Transparent Application Failover (TAF) can mask many failures from users, preserving the state of their applications and resuming queries that had been in progress at the time of the failure. Developers can further extend these capabilities by building applications that leverage TAF and make all failures, including those affecting transactions, transparent to users.
|
Additional Information:
See the Oracle8i Tuning for more information about Transparent Application Failover. |
Recovery Manager is a utility that manages the processes of creating backups of all database files (datafiles, control files, and archived redo log files) and restoring or recovering files from backups.
|
Additional Information:
See the Oracle8i Backup and Recovery Guide for a full description of Recovery Manager. |
Recovery Manager maintains a repository called the recovery catalog, which contains information about backup files and archived log files. Recovery Manager uses the recovery catalog to automate both restore operations and media recovery.
The recovery catalog contains:
The recovery catalog is maintained solely by Recovery Manager. The database server of the backed-up database never accesses the recovery catalog directly. Recovery Manager propagates information about backup datafile sets, archived redo logs, backup control files, and datafile copies into the recovery catalog for long-term retention.
When doing a restore, Recovery Manager extracts the appropriate information from the recovery catalog and passes it to the database server. The server performs various integrity checks on the input files specified for a restore. Incorrect behavior by Recovery Manager cannot corrupt the database.
The recovery catalog is stored in an Oracle database. It is the database administrator's responsibility to make such a database available to Recovery Manager. Taking backups of the recovery catalog is also the database administrator's responsibility. Since the recovery catalog is stored in an Oracle database, you can use Recovery Manager to back it up.
If the recovery catalog is destroyed and no backups are available, then it can be partially reconstructed from the current control file or control file backups.
Use of a recovery catalog is not required, but is recommended. Since most information in the recovery catalog is also available from the control file, Recovery Manager supports an operational mode where it uses only the control file. This operational mode is appropriate for small databases where installation and administration of another database to serve as the recovery catalog would be burdensome.
Some Recovery Manager features are only available when a recovery catalog is used.
|
Additional Information:
See the Oracle8i Backup and Recovery Guide for information about creating the recovery catalog, and about which Recovery Manager features require use of a recovery catalog. |
Recovery Manager can parallelize its operations, establishing multiple logon sessions and conducting multiple operations in parallel by using non-blocking UPI. Concurrent operations must operate on disjoint sets of datafiles.
|
Attention: The Oracle8i Enterprise Edition allows unlimited parallelism. Oracle8i can only allocate one Recovery Manager channel at a time, thus limiting the parallelism to one stream. See Getting to Know Oracle8i for more information about the features available with Oracle8i and Oracle8i Enterprise Edition. |
Parallelization of the backup, copy, and restore commands is handled internally by the Recovery Manager. You only need to specify:
Recovery Manager executes commands serially, that is, it completes the previous command before starting the next command. Parallelism is exploited only within the context of a single command. Thus, if 10 datafile copies are desired, it is better to issue a single copy command that specifies all 10 copies rather than 10 separate copy commands.
The report and list commands provide information about backups and image copies. The output from these commands is written to the message log file.
The report command produces reports that can answer questions such as:
You can use the report need backup and report unrecoverable commands on a regular basis to ensure that the necessary backups are available to perform recovery, and that the recovery can be performed within a reasonable length of time. The report deletable command lists backup sets and datafile copies that can be deleted either because they are redundant or because they could never be used by a recover command.
A datafile is considered unrecoverable if an unlogged operation has been performed against a schema object residing in the datafile.
(A datafile that does not have a backup is not considered unrecoverable. Such datafiles can be recovered through the use of the create datafile command, provided that logs starting from when the file was created still exist.)
The list command queries the recovery catalog and produces a listing of its contents. You can use it to find out what backups or copies are available:
A database can operate in two distinct modes: NOARCHIVELOG mode (media recovery disabled) or ARCHIVELOG mode (media recovery enabled).
If a database is used in NOARCHIVELOG mode, the archiving of the online redo log is disabled. Information in the database's control file indicates that filled groups are not required to be archived. Therefore, as soon as a filled group becomes inactive, the group is available for reuse by the LGWR process.
NOARCHIVELOG mode protects a database only from instance failure, not from disk (media) failure. Only the most recent changes made to the database, stored in the groups of the online redo log, are available for crash recovery or instance recovery. This is sufficient to satisfy the needs of crash recovery and instance recovery, because Oracle will not overwrite an online redo log that might be needed until its changes have been safely recorded in the datafiles. However, it will not be possible to do media recovery.
If an Oracle database is operated in ARCHIVELOG mode, the archiving of the online redo log is enabled. Information in a database control file indicates that a group of filled online redo log files cannot be reused by LGWR until the group has been archived.
Figure 32-3 illustrates how the database's online redo log files are used in ARCHIVELOG mode and how the archived redo log is generated by the process archiving the filled groups (for example, ARC0 in this illustration).
ARCHIVELOG mode permits complete recovery from disk failure as well as instance failure, because all changes made to the database are permanently saved in an archived redo log.
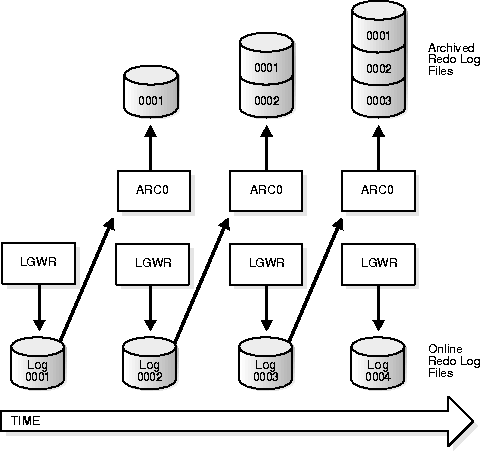
An instance can be configured to have an additional background process, the archiver (ARC0), automatically archive groups of online redo log files once they become inactive. Automatic archiving frees the database administrator from having to keep track of, and archive, filled groups manually. For this convenience alone, automatic archiving is the choice of most database systems that run in ARCHIVELOG mode. For heavy workloads, such as bulk loading of data, multiple archiver processes (up to ARC9) can be configured by setting the initialization parameter LOG_ARCHIVE_MAX_PROCESSES.
If you request automatic archiving at instance startup by setting the LOG_ARCHIVE_START initialization parameter, Oracle starts the number of ARCn processes specified by LOG_ARCHIVE_MAX_PROCESSES during instance startup. Otherwise, the ARCn processes are not started when the instance starts up.
However, the database administrator can interactively start or stop automatic archiving at any time. If automatic archiving was not specified to start at instance startup, and the administrator subsequently starts automatic archiving, Oracle creates the ARCn background process(es). ARCn then remains for the duration of the instance, even if automatic archiving is temporarily turned off and turned on again, although the number of ARCn processes can be changed dynamically by setting LOG_ARCHIVE_MAX_PROCESSES with the ALTER SYSTEM command.
ARCn always archives groups in order, beginning with the lowest sequence number. ARCn automatically archives filled groups as they become inactive. A record of every automatic archival is written in the ARCn trace file by the ARCn process. Each entry shows the time the archive started and stopped.
If ARCn encounters an error when attempting to archive a log group (for example, due to an invalid or filled destination), ARCn continues trying to archive the group. An error is also written in the ARCn trace file and the ALERT file. If the problem is not resolved, eventually all online redo log groups become full, yet not archived, and the system halts because no group is available to LGWR. Therefore, if problems are detected, you should either resolve the problem so that ARCn can continue archiving (such as by changing the archive destination) or manually archive groups until the problem is resolved.
If a database is operating in ARCHIVELOG mode, the database administrator can manually archive the filled groups of inactive online redo log files, as necessary, whether or not automatic archiving is enabled or disabled. If automatic archiving is disabled, the database administrator is responsible for manually archiving all filled groups.
For most systems, automatic archiving is chosen because the administrator does not have to watch for a group to become inactive and available for archiving. Furthermore, if automatic archiving is disabled and manual archiving is not performed fast enough, database operation can be suspended temporarily whenever LGWR is forced to wait for an inactive group to become available for reuse.
The manual archiving option is provided so that the database administrator can:
When a group is archived manually, the user process issuing the statement to archive a group actually performs the process of archiving the group. Even if the ARCn background process is present for the associated instance, it is the user process that archives the group of online redo log files.
The control file of a database is a small binary file necessary for the database to start and operate successfully. A control file is updated continuously by Oracle during database use, so it must be available for writing whenever the database is open. If for some reason the control file is not accessible, the database will not function properly.
Each control file is associated with only one Oracle database.
A control file contains information about the associated database that is required for the database to be accessed by an instance, both at startup and during normal operation. A control file's information can be modified only by Oracle; no database administrator or end-user can edit a database's control file.
Among other things, a control file contains information such as
The database name and timestamp originate at database creation. The database's name is taken from either the name specified by the initialization parameter DB_NAME or the name used in the CREATE DATABASE statement.
Each time that a datafile or an online redo log file is added to, renamed in, or dropped from the database, the control file is updated to reflect this physical structure change. These changes are recorded so that
Therefore, if you make a change to your database's physical structure, you should immediately make a backup of your control file.
|
Additional Information:
See Oracle8i Backup and Recovery Guide for information about backing up a database's control file. |
Control files also record information about checkpoints. Every three seconds, the checkpoint process (CKPT) records information in the control file about the checkpoint position in the online redo log. This information is used during database recovery to tell Oracle that all redo entries recorded before this point in the online redo log group are not necessary for database recovery; they were already written to the datafiles.
As with online redo log files, Oracle allows multiple, identical control files to be open concurrently and written for the same database.
By storing multiple control files for a single database on different disks, you can safeguard against a single point of failure with respect to control files. If a single disk that contained a control file crashes, the current instance fails when Oracle attempts to access the damaged control file. However, other copies of the current control file are available on different disks, so an instance can be restarted easily without the need for database recovery.
The permanent loss of all copies of a database's control file is a serious problem to safeguard against. If all control files of a database are permanently lost during operation (several disks fail), the instance is aborted and media recovery is required. Even so, media recovery is not straightforward if an older backup of a control file must be used because a current copy is not available. Therefore, it is strongly recommended that multiplexed control files be used with each database, with each copy stored on a different physical disk.
You can use Oracle mirrored logs, Oracle mirrored control files, and archive logs to recover from media failure, but some or all of the data may not be available while recovery is proceeding. To achieve a higher level of recovery, Oracle recommends that you use operating system or hardware data redundancy for at least the datafiles and the control files. This will make sure that any one media failure will be recoverable while the system is fully available.
No matter what backup and recovery scheme you devise for an Oracle database, backups of the database's datafiles and control files are absolutely necessary as part of the strategy to safeguard against potential media failures that can damage these files. The following sections provide a conceptual overview of the different types of backups that can be made and their usefulness in different recovery schemes.
|
Additional Information:
The Oracle8i Backup and Recovery Guide provides more details, along with guidelines for performing database backups. |
A whole database backup is an operating system backup of all datafiles and the control file that constitute an Oracle database. You can take a whole database backup when the database is shut down or while the database is open. You should not normally take a whole backup after an instance failure or other unusual circumstances.
Following a clean shutdown, all of the files that constitute a database are closed and consistent with respect to the current point in time. Thus, a whole backup taken after a shutdown can be used to recover to the point in time of that backup. A whole backup taken while the database is open is not consistent to a given point in time and must be recovered (with the online and archived redo log files) before the database can become available.
The datafiles obtained from a whole backup are useful in any type of media recovery scheme:
Because an archived redo log is not available to bring the database up to the current point in time, all database work performed since the backup must be repeated. Under special circumstances, a disk failure in NOARCHIVELOG mode can be fully recovered, but you should not rely on this.
After restoring the necessary datafiles from the whole backup, database recovery can continue by applying archived and current online redo log files to bring the restored datafiles up to the current point in time.
In summary, if a database is operated in NOARCHIVELOG mode, a consistent whole database backup is the only method to partially protect the database against a disk failure; if a database is operating in ARCHIVELOG mode, either a consistent or an inconsistent whole database backup can be used to restore damaged files as part of database recovery from a disk failure.
A partial database backup is any backup short of a whole backup, taken while the database is open or shut down. The following are all examples of partial database backups:
Partial backups are only useful for a database operating in ARCHIVELOG mode. Because an archived redo log is present, the datafiles restored from a partial backup can be made consistent with the rest of the database during recovery procedures.
A partial backup includes only some of the datafiles of a database. Individual or collections of specific datafiles can be backed up independently of the other datafiles, online redo log files, and control files of a database. You can back up a datafile while it is offline or online.
Choosing whether to take online or offline datafile backups depends only on the availability requirements of the data--online datafile backups are the only choice if the data being backed up must always be available.
Another form of a partial backup is a control file backup. Because a control file keeps track of the associated database's physical file structure, a backup of a database's control file should be made every time a structural change is made to the database.
Multiplexed control files safeguard against the loss of a single control file. However, if a disk failure damages the datafiles and incomplete recovery is desired, or a point-in-time recovery is desired, a backup of the control file that corresponds to the intended database structure should be used, not necessarily the current control file. Therefore, the use of multiplexed control files is not a substitute for control file backups taken every time the structure of a database is altered.
If you use Recovery Manager to restore the control file prior to incomplete or point-in-time recovery, Recovery Manager automatically restores the most suitable backup control file.
Export and Import are utilities used to move Oracle data in and out of Oracle databases. Export is a utility that writes data from an Oracle database to operating system files in an Oracle database format. Export files store information about schema objects created for a database. Import is a utility that reads Export files and restores the corresponding information into an existing database. Although Export and Import are designed for moving Oracle data, they can be used also as a supplemental method of protecting data in an Oracle database.
You can create backups of a read-only tablespace while the database is open. Immediately after making a tablespace read-only, you should back up the tablespace. As long as the tablespace remains read-only, there is no need to perform any further backups of it.
After you change a read-only tablespace to a read-write tablespace, you need to resume your normal backups of the tablespace, just as you do when you bring an offline read-write tablespace back online.
Bringing the datafiles of a read-only tablespace online does not make these files writeable, nor does it cause the file header to be updated. Thus it is not necessary to perform a backup of these files, as is necessary when you bring a writeable datafile back online.
In the event of a power failure, hardware failure, or any other system-interrupting disaster, Oracle offers the automated standby database feature. The standby database is intended for sites where survivability and disaster recovery are of paramount importance. (Another option is to use database replication. This feature is described in Chapter 34, "Database Replication".)
The only way to ensure rapid recovery from a system failure or other disaster is to plan carefully. You must have a set plan with detailed procedures. Whether you are implementing a standby database or you have a single database system, you must have a plan for what to do in the event of a catastrophic failure.
Oracle provides a reliable and supported mechanism for implementing a standby database system to facilitate quick disaster recovery. This mechanism is called Automated Standby Database. Up to four standby systems can be maintained in a constant state of media recovery through the automatic shipping and application of log files archived at the primary site. In the event of a primary system failure, one of the standby systems can be activated, providing immediate system availability. Oracle provides commands and internal verifications for operations involved in the creation and maintenance of the standby systems, improving the reliability of the disaster recovery scheme.
A standby database uses the archived log information from the primary database, so it is ready to perform recovery and go online at any time. When the primary database archives its redo logs, the logs must be transferred to the remote site and applied to the standby database. The standby database is therefore always one or two logs behind the primary database in time and transaction history.
Automated Standby Database protects your data from extended outages such as power failures, or from physical disasters such as fire, floods, or earthquakes. Because the standby database is designed for disaster recovery, it ideally resides in a separate physical location from the primary database.
You can open the standby database read only. This allows you to use the database for reporting. When you open a standby database read only, redo logs are placed in a queue and are not applied. As soon as the database is returned to standby mode, the queued logs and newly arriving logs are applied.
|
Additional Information:
See the Oracle8i Backup and Recovery Guide for information about creating and maintaining standby databases. |