Release 8.1.5
A67773-01
Library |
Product |
Contents |
Index |
| Oracle8i Backup and Recovery Guide Release 8.1.5 A67773-01 |
|
![]()
![]()
This chapter introduces database concepts that are fundamental to backup and recovery. It is intended as a general overview. Subsequent chapters explore backup and recovery concepts in greater detail.
You will learn about the following topics:
Simply speaking, a backup is a copy of data. This copy includes important parts of your database such as the control file and datafiles. A backup is a safeguard against unexpected data loss and application errors; should you lose your original data, you can use the backup to make it available again.
Backups are divided into physical backups and logical backups. Physical backups, which are the primary concern of this guide, are copies of physical database files. In contrast, logical backups contain data that you extract using the Oracle Export utility and store in a binary file. You can use logical backups to supplement physical backups. You can make physical backups using either the Oracle8i Recovery Manager utility or O/S utilities.
To restore a physical backup is to reconstruct it and make it available to the Oracle server. To recover a restored datafile is to update it using redo records, i.e., records of changes made to the database after the backup was taken. If you use Recovery Manager (RMAN), you can also recover restored datafiles with an incremental backup, which is a backup of a datafile that contain only changed data blocks.
Oracle performs crash recovery and instance recovery automatically after an instance failure. Instance recovery is an automatic procedure that involves two distinct operations: rolling forward the backup to a more current time by applying online redo records and rolling back all changes made in uncommitted transactions to their original state.
In contrast to instance recovery, media recovery requires you to issue recovery commands. If you use RMAN, then you issue the recover command to apply archived redo logs or incremental backups to the datafiles. RMAN automatically selects the appropriate incremental backups or redo logs and applies them. If you use SQL*Plus, you can issue the RECOVER or ALTER DATABASE RECOVER statements to apply the archived logs.
Figure 1-1 illustrates the basic principle of backing up, restoring, and performing media recovery on a database:
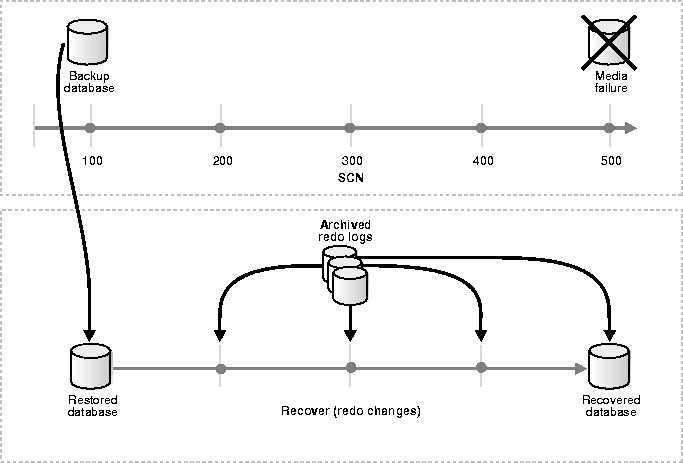
Recovery in general refers to the various operations involved in restoring, rolling forward, and rolling back a backup. Backup and recovery in general refers to the various strategies and operations involved in protecting your database against data loss and reconstructing the data should that loss occur.
See Also: For an overview of Recovery Manager features, see Chapter 4, "Recovery Manager Concepts". To learn how to perform O/S backup and recovery, see Chapter 13, "Performing Operating System Backups" and Chapter 14, "Performing Operating System Recovery".
To understand the basics of backup and recovery, you need to understand how Oracle records changes to a database. Every time a change is made against the database, Oracle generates a record of the change in the redo log buffer in memory. This record is called a redo record. Oracle records both committed and uncommitted changes in redo log buffers.
Oracle frequently writes the redo log buffers to the online redo log, which is on disk. The online redo log is constituted by at least two online redo log files. Oracle writes to these logs in a circular fashion: first it writes to one log file, then switches to the next available file when the current log is full.
Depending on whether Oracle runs in ARCHIVELOG or NOARCHIVELOG mode, the system begins archiving the redo information in the non-current online redo log file by copying the file to specified locations on disk. The online and archived redo logs are crucial for recovery since they contain records of all changes to the database.
See Also: For an overview of the online and archived redo logs, see Oracle8i Concepts. To learn the basics of administering these data structures, see the Oracle8i Administrator's Guide. To learn how to manage these structures for backup and recovery, see Chapter 2, "Managing Data Structures".
A physical backup is a snapshot of a datafile, tablespace, or database at a certain time. If you make periodic backups of a database, then should you lose some of the data on your original database, you can perform media recovery using the backups. During media recovery, you apply redo records or incremental backups to your latest backup to make the database current again. If the backup was a consistent backup, then you can also restore the backup without performing recovery.
Oracle enables you to restore an older backup and apply only some redo data, thereby recovering the database to a specified time or SCN. This type of recovery is called incomplete recovery. You must open your database with a RESETLOGS operation after performing incomplete recovery in order to reset the online redo logs.
An example will help illustrate the concept of media recovery. Assume that you make a backup of your database at noon. Starting at noon, one change to the database is made every second. The redo logs switch three times over the next hour, and because the database runs in ARCHIVELOG mode, these redo logs are archived to disk. At one p.m. your disk drive fails. Fortunately, you can restore your noon whole database backup onto a functional disk drive and, using the archived redo logs to recover the database to one p.m., reconstruct the changes.
See Also: To learn how to make consistent backups using O/S methods, see "Making Consistent Whole Database Backups". To learn how to perform media recovery, see Chapter 14, "Performing Operating System Recovery".
Although backup and recovery operations can sometimes be complicated, the basic principles for developing an effective strategy are simple:
Most backup and recovery techniques are variations on these principles. So long as you have backups of your datafiles, control files, and archived redo logs in safe storage, then even if a fire were to destroy your hardware, you can recreate your original database.
A sophisticated and effective disaster prevention technique is to maintain a standby database, which is an exact replicate of your production database that you can update automatically with archived redo logs propagated through a Net8 connection.
See Also: To learn more about managing important data structures such as the online redo logs, see Chapter 2, "Managing Data Structures". To learn more about developing a backup and recovery strategy, see Chapter 3, "Developing a Backup and Recovery Strategy". To learn how to maintain a standby database, see Chapter 16, "Managing a Standby Database".
Before you can begin thinking seriously about backup and recovery strategy, you need to understand the physical data structures that are relevant for backup and recovery operations. In this section we will briefly discuss:
This manual will cover these topics in more detail in subsequent chapters.
See Also: For a complete overview of the Oracle8i architecture, see Oracle8i Concepts. To learn how to manage these data structures, see the Oracle8i Administrator's Guide.
Every Oracle database has one or more physical datafiles. A database's datafiles, which belong to logical structures called tablespaces, contain the database data. The datafile is divided into smaller units called data blocks. The data of logical database structures such as tables and indexes is physically located in the blocks of the datafiles allocated for a database.
The first block of every datafile is the header. The header includes important information such as file size, block size, tablespace, creation timestamp, and checkpoint SCN (see "System Change Number (SCN)"). Whenever you open a database, Oracle checks the datafile header information against the information stored in the control file to determine whether recovery is necessary.
Oracle reads the data in a datafile during normal operation and stores it in the in-memory buffer cache. For example, assume that a user wants to access some data in a table. If the requested information is not already in the buffer cache, Oracle reads it from the appropriate datafiles and stores it in memory.
The background process DBWn, known as the database writer or db writer, writes modified buffers to disk. Typically, there is a time lapse between the time when an Oracle server process changes a block in the buffer cache and the time when DBWn writes it to disk. The more data that accumulates in memory without being written to disk, the longer the instance recovery time, since a crash or media failure will force Oracle to apply redo data from the current online log to recover those changes. Minimizing this time, known as the mean time to recover (MTTR), is an important aspect of backup and recovery strategy.
See Also: For more information on parameters that you can use to influence the MTTR, see Oracle8i Tuning.
Every Oracle database has a control file. A control file is an extremely important binary file that contains the operating system filenames of all other files constituting the database. It also contains consistency information that is used during recovery, such as:
When multiplexing the control file, you configure Oracle to write multiple copies of it in order to protect it against loss. If your operating system supports disk mirroring, you can also mirroring the control file, i.e., configure the O/S to write a copy of the control file to multiple disks.
See Also: For more information about multiplexing and mirroring the control file, see "Maintaining Multiple Control Files". For general information about managing the control file, see Oracle8i Administrator's Guide.
Every time you mount an Oracle database, its control file is used to identify the datafiles and online redo log files that must be opened for database operation. If the physical makeup of the database changes, e.g., a new datafile or redo log file is created, then Oracle modifies the database's control file to reflect the change.
Back up the control file whenever the set of files that makes up the database changes. Examples of structural changes include adding, dropping, or altering datafiles or tablespaces and adding or dropping online redo logs.
See Also: To learn how to back up the control file, see "Backing Up the Control File After Structural Changes".
Every database contains one or more rollback segments, which are logical structures contained in datafiles. Whenever a transaction modifies a data block, a rollback segment records the state of the information before it changed.
Oracle uses rollback segments for a variety of operations. In general, the rollback segments of a database store the old values of data changed by uncommitted transactions. Oracle can use the information in a rollback segment during database recovery to undo any uncommitted changes applied from the redo log to the datafiles, putting the data into a consistent state.
For example, a user changes a row value in a table from 5 to 7. The redo log keeps a record of this change while the rollback segment stores the old value. Before the user can commit the transaction, the power goes out. After power is restored, the database performs a crash recovery operation: it uses the redo log to roll forward the value from 5 to 7, then uses the rollback segment to undo the uncommitted change from 7 to 5.
Every Oracle database has a set of two or more online redo log files. Oracle assigns every redo log file a unique log sequence number to identify it. The set of redo log files for a database is collectively known as the database's redo log. Oracle uses the redo log to record all changes made to the database.
Oracle records every change in a redo record, which is an entry in the redo buffer describing what has changed. For example, assume a user updates a column value in a payroll table from 5 to 7. Oracle records the old value in a rollback segment and the new value in a redo record. Because the redo log stores every change to the database, the redo record for this transaction actually contains three parts:
If you then commit the update to the payroll table, Oracle generates another redo record and assigns the change an SCN. In this way, the system maintains a careful watch over everything that occurs in the database.
The log writer background process (LGWR) writes to online redo log files in a circular fashion: when it fills the current online redo log, LGWR writes to the next available inactive redo log. LGWR cycles through the online redo log files in the database, writing over old redo data. Filled redo log files are available for reuse depending on whether archiving is enabled:
The system change number (SCN) is an ever-increasing value that uniquely identifies a committed version of the database. Every time a user commits a transaction, Oracle records a new SCN. You can obtain SCNs in a number of ways, for example, from the alert log. You can then use the SCN as an identifier for purposes of recovery. For example, you can perform an incomplete recovery of a database up to SCN 1030.
Oracle uses SCNs in control files, datafile headers, and redo records. Every redo log file has both a log sequence number and low and high SCN. The low SCN records the lowest SCN recorded in the log file, while the high SCN records the highest SCN in the log file.
Redo logs are crucial for recovery. For example, suppose that a power outage prevents Oracle from permanently writing modified data to the datafiles. In this situation, you can use an old version of the datafiles combined with the changes recorded in the online and archived redo logs to reconstruct what was lost.
To protect against redo log failure, Oracle allows the redo log to be multiplexed. When Oracle multiplexes the online redo log, it maintains two or more copies of the redo log on different disks. Note that you should not back up the online redo log files, nor should you ever need to restore them; you keep redo logs by archiving them.
See Also: For more information on managing the online redo log for backup and recovery, see "Managing the Online Redo Log". For a general discussion see Oracle8i Administrator's Guide.
An archived redo log is an online redo log that Oracle has filled with redo entries, rendered inactive, and copied to one or more destinations specified in the parameter file. You can run Oracle in either of two archive modes:
|
ARCHIVELOG |
Oracle archives the filled online redo log files before reusing them in the cycle. |
|
NOARCHIVELOG |
Oracle does not archive the filled online redo log files before reusing them in the cycle. |
Running the database in ARCHIVELOG mode has the following consequences:
Running the database in NOARCHIVELOG mode has the following consequences:
See Also: For more information on archiving redo logs, see "Managing the Archived Redo Logs" and Oracle8i Administrator's Guide. For more information about the standby database option, see Chapter 16, "Managing a Standby Database".
A physical backup is a copy of a datafile, control file, or archived redo log that you store as a safeguard against data loss. When thinking about a backup strategy, consider these questions:
Imagine the magnitude of lost revenue--not to mention the degree of customer dissatisfaction--if the production database of a catalog company, express delivery service, bank, or airline suddenly became unavailable, even for just 5 or 10 minutes. Alternatively, imagine that you lose important payroll datafiles due to a hard disk crash and cannot restore or recover them because you do not have a backup. Depending on the size and value of the lost information, the results can be devastating.
By making frequent backups, you ensure that you can restore at least some of your lost data. If you run you database in ARCHIVELOG mode, you can apply redo to restored backups in order to reconstruct all lost changes.
A backup is a safeguard against data loss or corruption. Unfortunately, you can lose or corrupt data in a variety of ways; you should consider these various possibilities when developing your backup strategy. The most common types of failures causing data loss are:
Your database contains a wide variety of types of data. When developing your backup strategy, you must decide what information you want to copy. You have the following basic backup types:
The basic principle you should use when deciding what to back up is to prioritize data depending on its importance and the degree to which it changes. Archived redo logs do not change, for example, but they are crucial for recovering your database, so you should maintain multiple copies if possible. A different case is a group of important expense account tables that users constantly update. You should probably back up this tablespace frequently; in this way, you will not have to apply as much redo data during recovery.
You can combine types of backups in a variety of ways. For example, you may prudently decide to take weekly whole database backups, which ensures that you have a relatively current copy of your original database information. You can then take daily backups of your most-accessed tablespaces. You can also multiplex the all-important control file and online redo logs as an additional safeguard.
You have a choice between three basic methods for making backups. You can:
See Also: To learn more about choosing backup methods, see "Choosing Backup Methods". For an overview of Recovery Manager features, see Chapter 4, "Recovery Manager Concepts".
RMAN is a powerful and versatile program that allows you to make a backup or image copy of your data. When you specify files or archived logs using the RMAN backup command, RMAN creates a backup set as output.
A backup set is one or more datafiles, control files, or archived redo logs that are written in an RMAN-specific format; it requires you to use the RMAN restore command for recovery operations. In contrast, when you use the copy command to create an image copy of a file, it is in an instance-usable format--you do not need to invoke RMAN to restore or recover it.
When you issue RMAN commands such as backup or copy, RMAN establishes a connection to an Oracle server session. The server session then backs up the specified datafile, control file, or archived log from the target database.
RMAN obtains the information it needs from either the control file or the optional recovery catalog. The recovery catalog is a central repository containing a variety of information useful for backup and recovery. Conveniently, RMAN automatically establishes the names and locations of all the files that you need to back up.
RMAN provides several advantages. One crucial advantage to using RMAN is its incremental backup feature. In traditional backup methods, you must perform a full backup in which you back up all the data blocks ever used in a datafile. The incremental backup feature allows you to back up only those data blocks that have changed since a previous backup.
Using RMAN, you can perform two types of incremental backups: a differential backup or a cumulative backup. In a differential level n incremental backup, you back up all blocks that have changed since the most recent level n or lower backup. For example, in a differential level 2 backup, RMAN determines which level 1 or level 2 backup occurred most recently and backs up all blocks modified since that backup.
In a cumulative level n backup, RMAN backs up all the blocks used since the most recent backup at level n-1 or less. For example, in a cumulative level 3 backup, RMAN determines which level 2 or level 1 backup occurred most recently and backs up all blocks used since that backup.
You can easily integrate RMAN with a media manager. A media manager is a vendor-supplied software package that allows you to back up to archival media such as tape. RMAN coordinates with the media manager to move data between the disk and storage devices. If the media manager is capable of making a proxy copy, then it can perform the data transfer in backup and restore operations.
See Also: For an introduction to RMAN, see Chapter 4, "Recovery Manager Concepts". To learn how to make backups and copies with RMAN, see Chapter 8, "Making Backups and Copies with Recovery Manager". For information about incremental backups, see "Incremental Backups".
If you do not want to use RMAN, you can use operating system commands such as the UNIX cp command to make backups. You can also automate backup operations by writing scripts.
You can make a backup of the whole database at once or supplement a whole database backup with backups of individual tablespaces, datafiles, control files, and archived logs. You can use O/S commands to perform these backups.
See Also: To learn how to make O/S backups, see Chapter 13, "Performing Operating System Backups".
You can supplement physical backups by using the Export utility to make logical backups of your data. Logical backups store information about the schema objects created for a database. The Export utility writes data from a database into Oracle files in a proprietary format. You can then import this data into a database using the Import utility.
See Also: To learn how to use the Export and Import utilities, see Oracle8i Utilities.
You can use RMAN or O/S commands to make an inconsistent backup or a consistent backup. An inconsistent backup is a backup of one or more database files that you make while the database is open or after the database has been shut down abnormally. A consistent backup is a backup of one or more database files that you make after the database has been closed cleanly. Unlike an inconsistent backup, a consistent backup does not require instance recovery after it is restored.
Whether you make consistent or inconsistent backups depends on a number of factors. If your database must be open and available all the time, then inconsistent backups are your only option. If there are recurring periods of minimal use, then you may decide to take regular consistent backups of the whole database and supplement them with online backups of often-used tablespaces.
When you back up the entire database after shutting it down cleanly, it is called a consistent whole database backup. The basic procedure for a consistent whole database backup is:
If you are operating in NOARCHIVELOG mode, shut down the database cleanly before making a cold backup. If you do not, the database is inconsistent with respect to an SCN and requires instance recovery to become consistent. The backup may be rendered unusable.
You can make backups of tablespaces, datafiles, control files, and archived redo logs while the database is open. If possible, take the desired tablespace offline and back up the datafiles. If the tablespace must remain online, and you are using O/S methods to back up the datafiles, first place the tablespace in hot backup mode by issuing the ALTER TABLESPACE ... BEGIN BACKUP command. Take it out of hot backup mode by issuing ALTER TABLESPACE ... END BACKUP. You do not need to issue this command when using RMAN.
See Also: To learn how to make online backups using O/S methods, see "Backing Up Online Tablespaces and Datafiles". To learn how to use RMAN to make backups, see Chapter 8, "Making Backups and Copies with Recovery Manager".
Tailor your backup strategy to the needs of your business. For example, if you can afford to lose data in the event of a disk failure, you may not need to perform backups very often. The advantage of taking infrequent backups is that you free Oracle's resources for other operations. The disadvantage is that you may end up losing data or increasing recovery time.
In a different scenario, if your database must be available twenty-four hours a day, seven days a week, then you should make online backups of your database frequently. In this case, you may decide to take daily hot backups, multiplex (i.e., have multiple copies of) your online redo logs, and archive your redo logs to several different locations. You can even maintain a standby database in a different city that is a constantly updated replica of your original database.
See Also: To learn important considerations for an effective backup strategy, see Chapter 3, "Developing a Backup and Recovery Strategy".
As we have seen, basic media recovery involves two parts: restoring a physical backup and updating it with database changes. The most important aspect of recovery is making sure that all datafiles are consistent with respect to the same SCN. Oracle has integrity checks that prevent you from opening the database until all datafiles are consistent with one another.
When preparing a recovery strategy, make sure you understand the answers to these questions:
In every type of instance or media recovery (except media recovery using RMAN incremental backups), Oracle sequentially applies redo data to data blocks. Oracle uses information in the control file and datafile headers to ascertain whether recovery is necessary.
Recovery has two parts: rolling forward and rolling back. When Oracle rolls forward, it applies redo records to the corresponding data blocks. Oracle systematically goes through the redo log to determine which changes it needs to apply to which blocks, and then changes the blocks. For example, if a user adds a row to a table, but the server crashes before it can save the change to disk, Oracle can use the redo record for this transaction to update the data block to reflect the new row.
During the rolling back phase, Oracle applies rollback segments to the datafiles. The rollback information is stored in transaction tables. Oracle searches through the table for uncommitted transactions, undoing any that it finds. For example, if the user never committed the SQL statement that added the row, then Oracle will discover this fact in a transaction table and undo the change.
If the database is mounted during recovery, rollback occurs only when the database is opened. If the database is open and a tablespace is offline during recovery, rollback for that tablespace occurs when the tablespaces is brought online.
See Also: To learn more about the mechanics of Oracle recovery, see Oracle8i Concepts.
There are three basic types of recovery: instance recovery, crash recovery, and media recovery. Oracle performs the first two types of recovery automatically at instance startup; only media recovery requires you to issue commands.
Instance recovery, which is only possible in an OPS configuration, occurs in an open database when one instance discovers that another instance has crashed. A surviving instance automatically uses the redo log to recover the committed data in the database buffers that was lost when the instance failed. Further, Oracle undoes any transactions that were in progress on the failed instance when it crashed and then clears any locks held by the crashed instance after recovery is complete.
Crash recovery occurs when either a single-instance database crashes or all instances of a multi-instance database crash. In crash recovery, an instance must first open the database and then execute recovery operations. In general, the first instance to open the database after a crash or SHUTDOWN ABORT automatically performs crash recovery.
Unlike crash and instance recovery, media recovery is executed on your command. In media recovery, you use online and archived redo logs and (if using RMAN) incremental backups to make a restored backup current or to update it to a specific time. It is called media recovery because you usually perform it in response to media failure.
Media recovery uses redo records or (if you use RMAN) incremental backups to recover restored datafiles either to the present or to a specified non-current time. When performing media recovery, you can recover the whole database, a tablespace, or a datafile. In any case, you always use a restored backup to perform the recovery. The principal division in media recovery is between complete recovery and incomplete recovery.
Complete recovery involves using redo data or incremental backups combined with a backup of a database, tablespace, or datafile to update it to the most current point in time. It is called complete because Oracle applies all of the redo changes to the backup. Typically, you perform media recovery after a media failure damages datafiles or the control file.
You can perform complete recovery on a database, tablespace, or datafile. If you are performing complete recovery on the whole database, then you must:
If you are performing complete recovery on a tablespace or datafile, then you must:
See Also: To learn how to perform complete recovery with RMAN, see "Performing Complete Recovery". To learn how to perform complete media recovery using O/S methods, see "Performing Complete Media Recovery".
Incomplete recovery uses a backup to produce a non-current version of the database. In other words, you do not apply all of the redo data generated since the most recent backup. You usually perform incomplete recovery when:
To perform incomplete media recovery, you must restore all datafiles from backups created prior to the time to which you want to recover and then open the database with the RESETLOGS option when recovery completes. The RESETLOGS operation creates a new incarnation of the database. All archived redo logs generated after the point of the RESETLOGS on the old incarnation are invalid on the new incarnation.
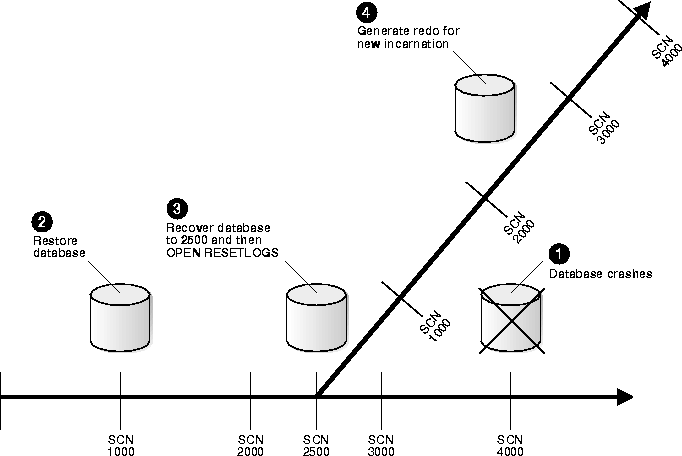
Figure 1-2 shows the case of a database that can only be recovered to SCN 2500 because an archived redo log is missing. At SCN 4000, the database crashes. You restore the SCN 1000 backup and prepare for complete recovery. Unfortunately, one of your archived redo logs is corrupted. The log before the missing log contains SCN 2500, so you recover to this point and open with the RESETLOGS option.
As the diagram illustrates, you generate new changes in the new incarnation of the database, eventually reaching SCN 4000. The changes between SCN 2500 and SCN 4000 for the new incarnation of the database will be completely different from the changes between SCN 2500 and SCN 4000 for the old incarnation. Oracle will not allow you to apply logs from an old incarnation to the new incarnation. You cannot restore backups from before SCN 2500 in the old incarnation to the new incarnation.
The tablespace point-in-time recovery (TSPITR) feature enables you to recover one or more tablespaces to a point-in-time that is different from the rest of the database. TSPITR is most useful when you want to:
See Also: To learn how to perform TSPITR using RMAN, see Appendix A, "Performing Tablespace Point-in-Time Recovery with Recovery Manager". To learn how to perform O/S TSPITR, see Appendix B, "Performing Operating System Tablespace Point-in-Time Recovery".
Since you are not completely recovering the database to the most current time, you must tell Oracle when to terminate recovery. You can perform the following types of recovery.
See Also: To learn how to perform incomplete recovery with RMAN, see "Performing Incomplete Recovery". To learn how to perform incomplete media recovery using O/S methods, see "Performing Incomplete Media Recovery".
Whenever you perform incomplete recovery, you must reset the online redo logs when you open the database. The new version of the reset database is called a new incarnation.
Opening the database with the RESETLOGS option informs Oracle that you want to discard some redo and prevents Oracle from ever applying the discarded redo in any recovery you might do in the future. For example, if the latest log sequence number for your database is 100, and you then recover to log sequence number 50 and do not open RESETLOGS, eventually your database will reach log sequence number 100 again. If you then try to recover the database using the old archived log 100, you run the risk of corrupting your datafiles or generating internal errors.
Whenever you open the database with the RESETLOGS option, all datafiles get a new SCN and timestamp. Archived redo logs also have these two values in their header. Because Oracle will not apply an archived redo log to a datafile unless the SCN and timestamps match, the RESETLOGS operations prevents you from corrupting your datafiles with old archived logs.
After resetting the online redo logs, make a whole database backup. In general, backups made before a RESETLOGS operation are not legal in the new incarnation. There is, however, an exception to the rule: you can restore a pre-RESETLOGS backup only if Oracle does not need to access archived redo logs from before the RESETLOGS to perform recovery.
It is possible to restore these pre-RESETLOGS backups in a new incarnation:
Note that you are prevented from restoring backups of read-write tablespaces that were not made immediately before the RESETLOGS. This restriction obtains even if no changes were made to the datafiles in the read-write tablespace between the backup and the RESETLOGS. Because the checkpoint in the datafile header of a backup will be older than the checkpoint in the control file, Oracle has to search the archived logs to determine whether changes need to be applied--and the pre-RESETLOGS archived logs are not valid in the new incarnation.
See Also: To learn how to restart the database in RESETLOGS mode, see "Opening the Database after Media Recovery".
You have a choice between two basic methods for recovering physical files. You can:
The basic RMAN recovery commands are restore and recover. Use RMAN to restore datafiles from backup sets or from image copies on disk, either to their current location or to a new location. You can also restore backup sets containing archived redo logs.
If you use a recovery catalog, RMAN has a record containing all the essential metadata concerning every backup you have taken. If you do not use a recovery catalog, RMAN uses the control file for necessary metadata.
Use the RMAN recover command to perform media recovery and apply incremental backups. You can use the set until command to perform incomplete media recovery. RMAN completely automates the procedure for recovering and restoring your backups and copies.
See Also: To learn how to restore database files, see "Restoring Datafiles, Control Files, and Archived Redo Logs". To learn how to perform recovery with RMAN, see "Recovering Datafiles". For RMAN syntax, see Chapter 11, "Recovery Manager Command Syntax".
If you do not use RMAN, use the SQL*Plus utility to restore and recover your files. You can execute:
If your operating system supports Oracle Enterprise Manager, you can execute restore and recovery operations in a GUI environment. See the Oracle Enterprise Manager Administrator's Guide for more information.
In each case you can recover a database, tablespace, or datafile. Before performing recovery, you need to:
If you cannot restore a datafile to its original location, relocate the restored datafile and inform the control file of the new location.
After these steps are completed, issue either the RMAN recover command or the SQL*Plus RECOVER statement.
See Also: To learn how to perform recovery with RMAN, see Chapter 9, "Restoring and Recovering with Recovery Manager". To learn how to perform operating system recovery, see Chapter 14, "Performing Operating System Recovery".
To learn how to use the SQL*Plus utility, see the SQL*Plus User's Guide and Reference. For more information on the syntax of SQL commands, see the Oracle8i SQL Reference.