Counting Primes in a Jupyter Notebook¶
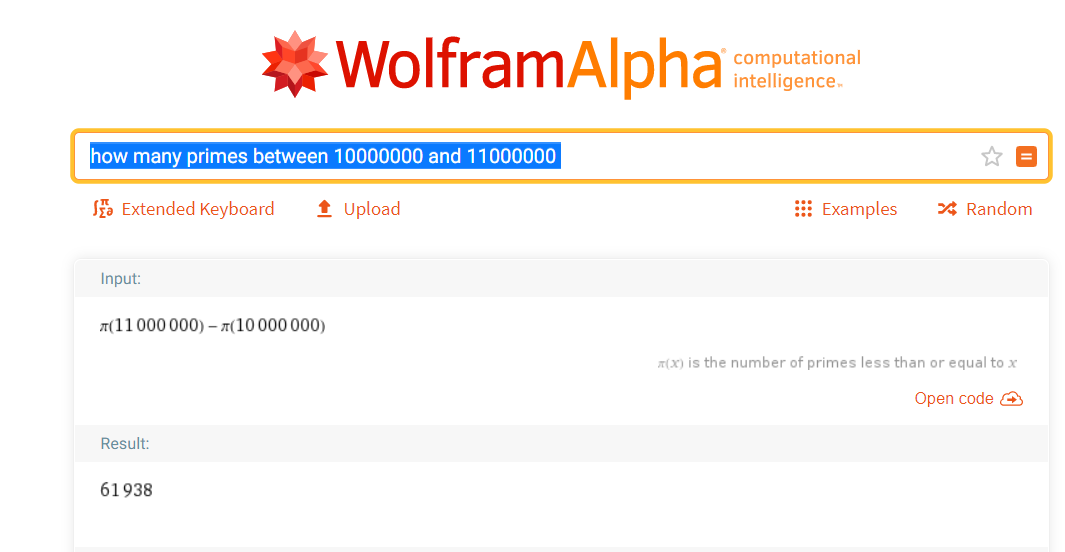
In a recent CTF, the following question was posed: how many primes are there between 10 million and 11 million? We consider various ways of answering this.
Python has a builtin prime test function. It's located in the sympy package. But there are other functions there that might be useful!
In [11]:
import time
import sympy
count = 0
start = time.process_time()
for i in range(10000001,11000000,2):
if sympy.isprime(i):
count += 1
print("number of primes is %d" % count)
print("Execution time: %f" % (time.process_time() - start))
This is a brute force approach, but at least we didn't bother to test the even numbers for primeality. The runtime isn't too bad. Can we do it faster?
In [20]:
import time
import sympy
count = 0
start = time.process_time()
x = [i for i in sympy.primerange(10000001,11000000)]
print("number of primes is %d" % len(x))
print("Execution time: %f" % (time.process_time() - start))
Improvement, but small. Any other useful functions?
In [16]:
import time
import sympy
start = time.process_time()
count = sympy.primepi(11000000)-sympy.primepi(10000000)
print("number of primes is %d" % count)
print("Execution time: %f" % (time.process_time() - start))
Probably the best we can do in Python. How well does this scale? Try billions instead of millions...
In [21]:
import time
import sympy
start = time.process_time()
count = sympy.primepi(11000000000)-sympy.primepi(10000000000)
print("number of primes is %d" % count)
print("Execution time: %f" % (time.process_time() - start))
Not bad! Moral of the story? There are several:
- Brute force is sometimes good enough.
- Avoid for loops in Python if you can.
- Use builtin functions when you can.
- Use Wolfram Alpha when you can.
In [ ]: